阅读报告:GPS: A Global Publish Subscribe Model for Multi-GPU Memory Management
post on 09 Jun 2022 about 5512words require 19min
CC BY 4.0 (除特别声明或转载文章外)
如果这些文字帮助到你,可以请我喝一杯咖啡~
阅读国际会议 ASPLOS、 USENIX 系列会议、PPoPP、或 IEEE、SC 等近三年发表的一篇正式科研论文(正式论文一般是英文双栏,大于 10 页),并撰写阅读报告(约 5-8 页左右,小四字体、单倍行距,若图片较多,可增加页数),报告内容包括:
- 相关背景
- 问题是什么
- 现有解决方案
- 作者的核心思想、创新点是在哪里
- 通过什么样的实验进行验证
- 对你的启发
我选择了《GPS: A Global Publish Subscribe Model for Multi-GPU Memory Management》,发表于 MICRO’21 并获得该届 Best Paper Nominee。相关下载链接见 PDF;我也曾在组会上分享过这篇论文。
相关背景与问题
近年来,随着数据的爆炸式增长、大数据技术的不断演化及人工智能算法的突破,GPU 等异构加速器作为高带宽、适合并行的硬件架构成为数据中心、超算中心的主流选择。通常来说,在这些场景中均会使用多 GPU 以提供更高性能,但对于其使用者来说充分管理硬件资源难度很大。主要困难之一是,本地和远程存储带宽相差数量级,互连带宽限制了应用的可扩展性。Figure 1 展示了 4 张 NVIDIA V100 GPU 组成的系统,在无限带宽(理想情况)、PCIe 6.0(预测)、PCIe 3.0 相对于单卡的平均加速比分别为 $3\times, 2\times, 0.7\times$。
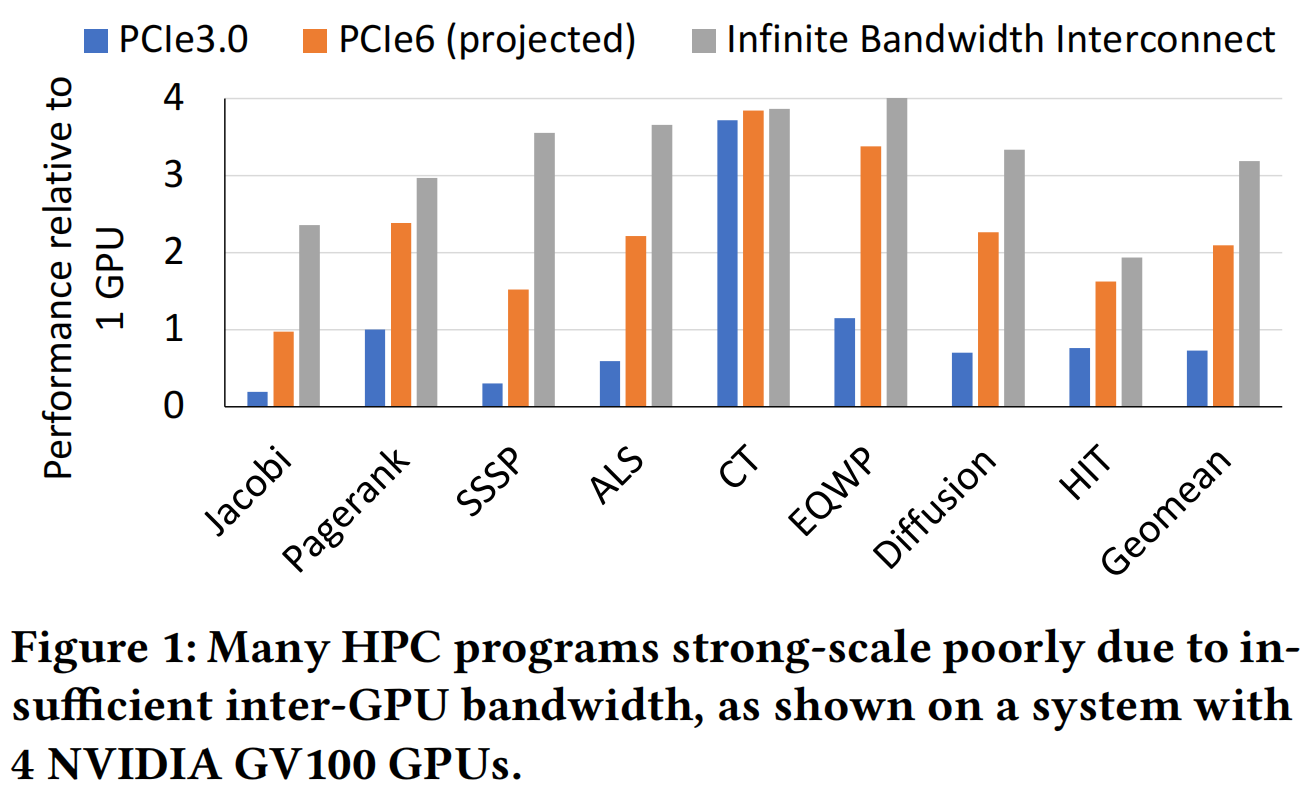
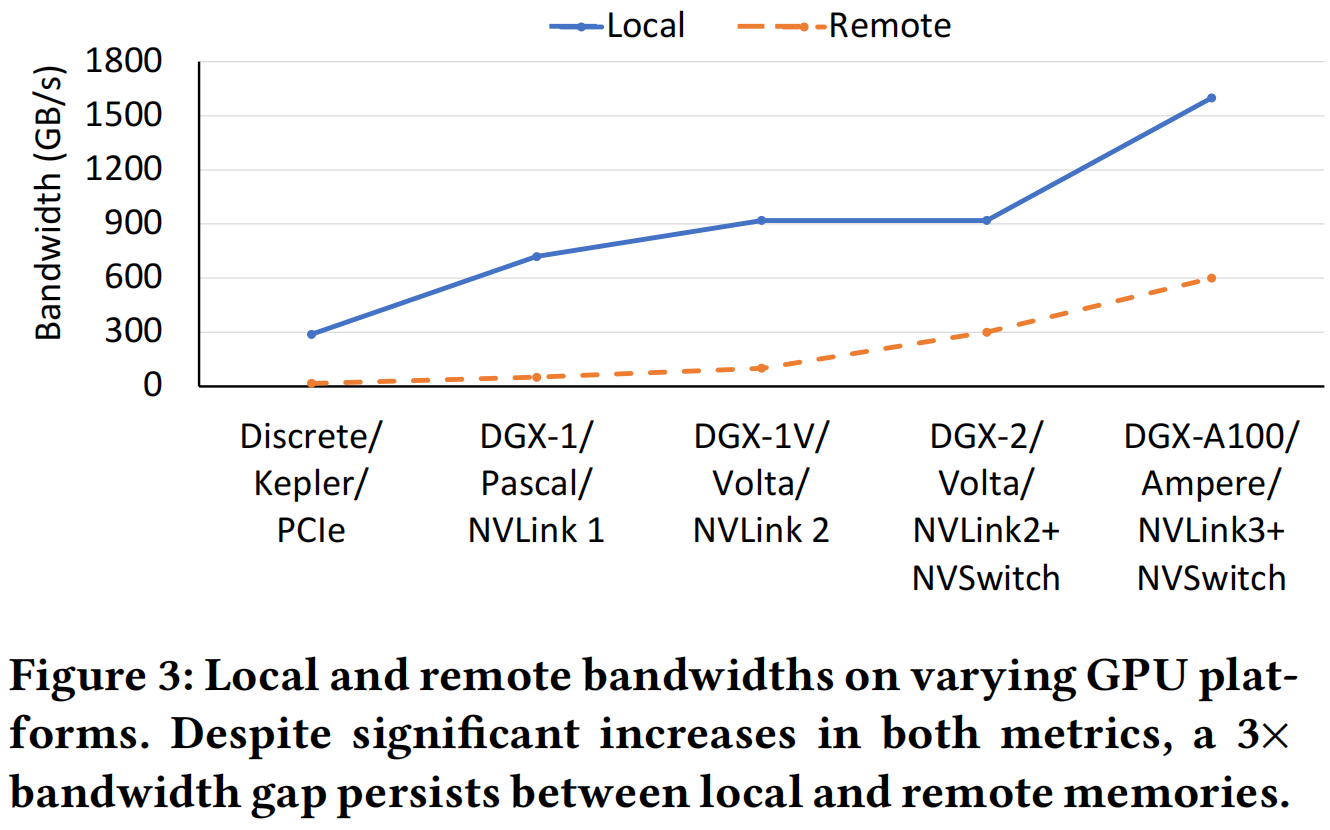
Figure 3 展示了互联带宽发展速度始终慢于本地带宽,存在大约三倍的差距。
现有解决方案
当前多 GPU 系统中有效管理数据的技术均存在不足,下面分小节介绍。Figure 4 展示了现有技术间的性能比较。
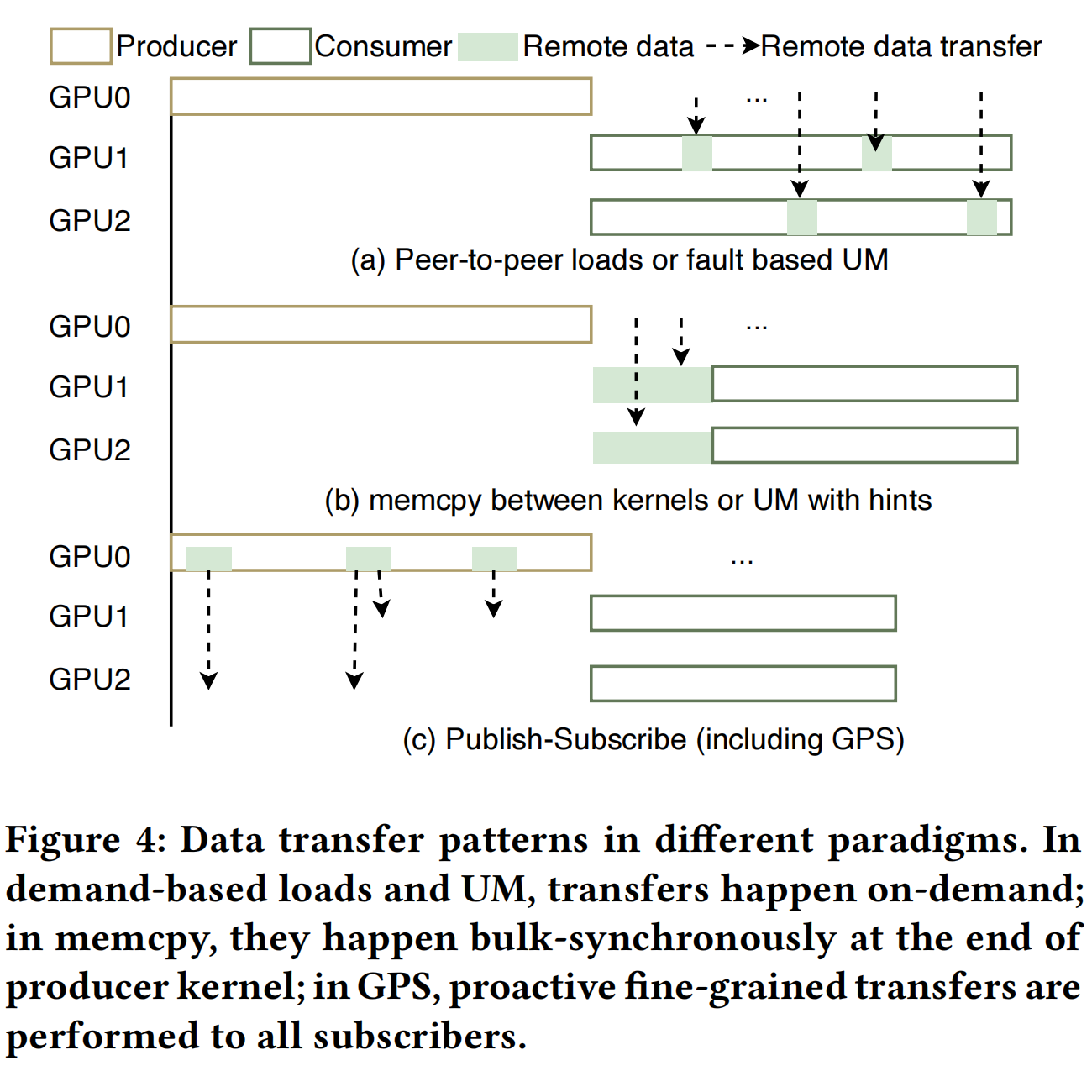
主机端启动 GPU 之间的 memcpy
这种方法需要精细调整以实现计算通信的流水。程序员可以通过 MPI、NCCL 等通信框架直接操作 GPU 缓冲区,但计算和通信的重叠仍然需要手动调整;学习成本增加,进一步加重程序员的负担。
也可以直接使用 GPU 点对点对等传输,一些现代的 GPU 其线程可以直接访问其他 GPU 的物理内存。这种方法的优势是可以细粒度执行,计算通信可以很好的重叠,启动开销低(只需要一方即可通信,不用同步),一种代表技术是 NVSHMEM,较之 MPI 更加高效。然而,严重受限于互连带宽的问题没有改善,读远程内存时延迟很高。
通过统一寻址内存(Unified Memory, UM)
UM 提供系统中任何处理器均可访问的单一且统一虚拟内存地址空间,以隐式、和程序员无关的方式支持 GPU 之间的数据移动,使用页面错误和迁移机制在 GPU 之间执行数据传输。然而,页面错误的性能开销巨大,UM 只是看起来美好。
当然,UM 可以通过显式提示的方式减少页面错误,从而实现细粒度数据共享的流水线预取和计算。但是这种方式不支持至少有一个 writer 和多个 reader 的页面复制,对有多个 reader 的页面的写将页面「折叠」到单个 GPU(通常是 writer),会触发昂贵的 TLB。
数据产生时主动传输
避免远程访问瓶颈的一种方法是,在生成数据后,提前将数据从生产 GPU 传输到消费 GPU,在需要时直接从本地内存读取数据。这种方法有助于实现强大的可伸缩性,提供了更多的机会使数据传输与计算重叠;同时改进了局部性,并确保关键路径负载享有更高的本地内存带宽。然而,只有一部分 GPU 将消耗数据的情况下,执行广泛的全对全传输会浪费 GPU 间的带宽。
作者的核心思想、创新点是在哪里
基于上述讨论,作者提出 GPS:一个全局发布-订阅的多显卡内存管理模型,提供了一组体系架构增强功能。GPS 订阅管理完全由发布-订阅处理单元处理,自动跟踪哪些 GPU 订阅共享内存页,同时主动向所有订户广播存储,使订户能够以高带宽从本地内存读取数据。GPS 通过驱动程序,在每个订阅 GPU 上本地复制这些页,且发布-订阅的过程可以解耦。
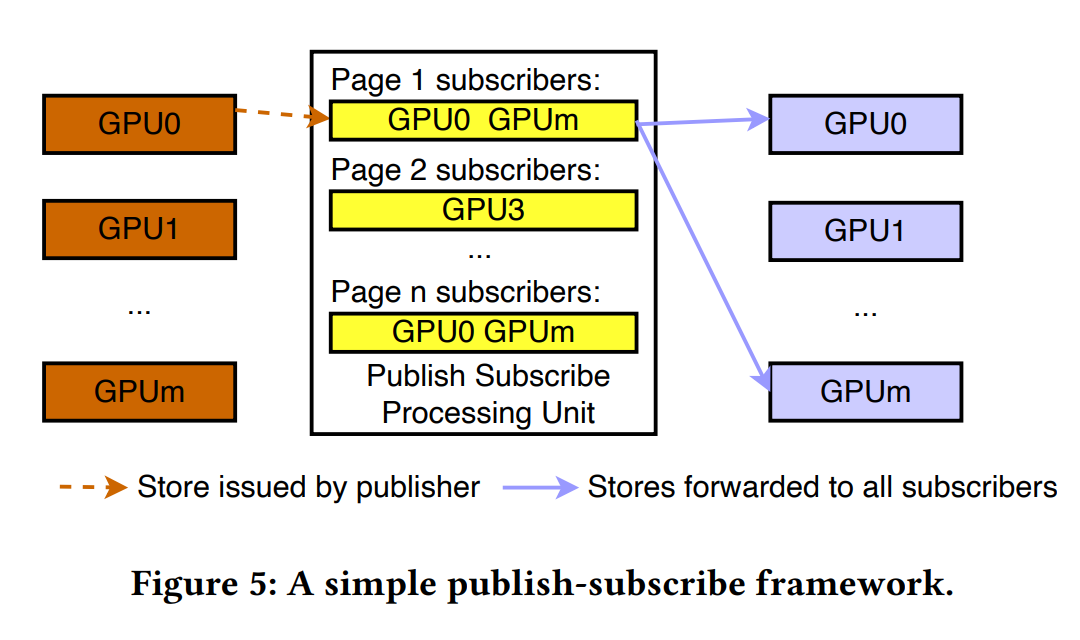
Figure 5 展示了一个简单的发布-订阅模型示例,它包含生成数据的发布者、请求特定更新的订阅者以及发布-订阅处理单元。
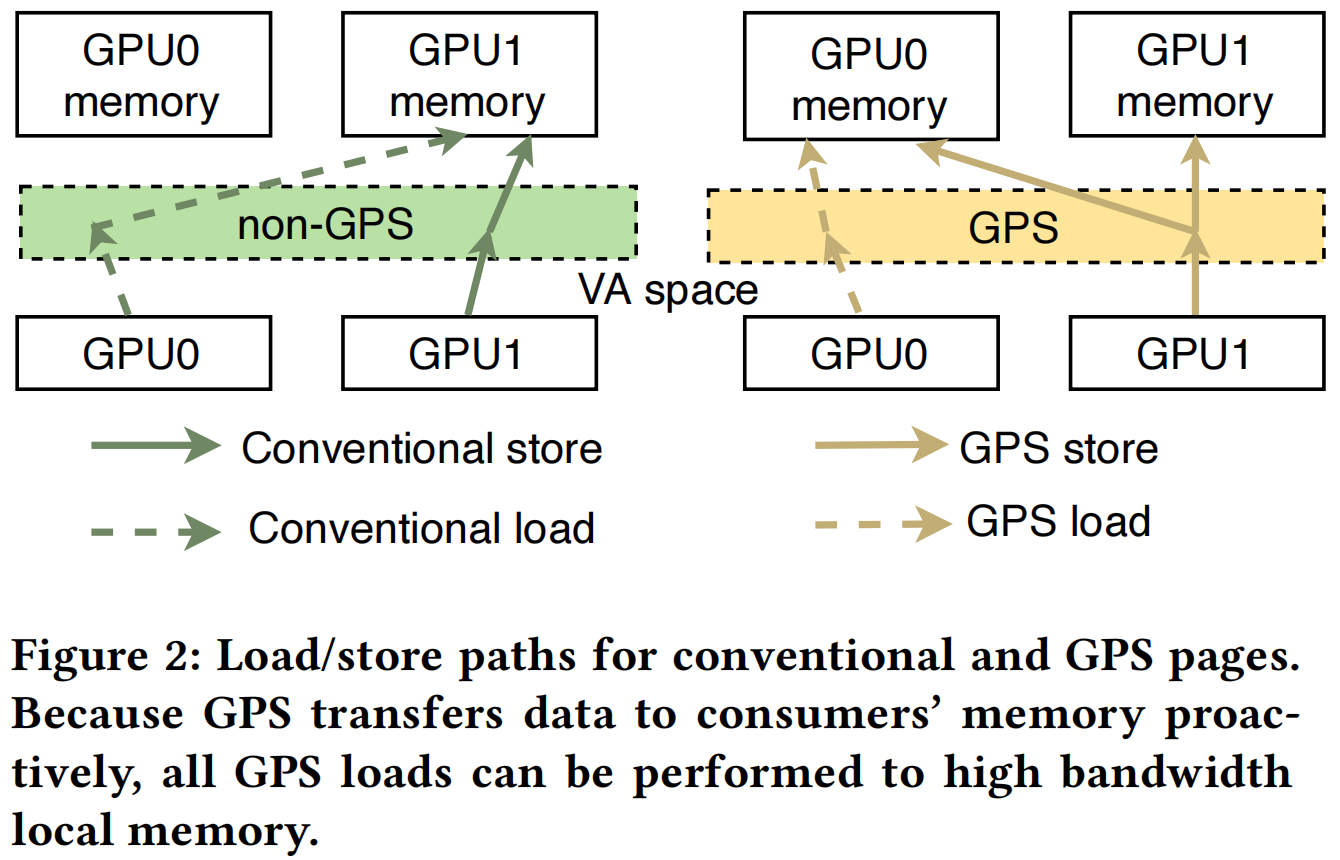
GPS 的读操作总是从本地返回,而 GPS 的写操作则广播给所有用户,Figure 2 展示了 GPS 的数据通路。传统的加载-存储访存模型根据物理内存位置导致本地或远程访问,后者会带来更多的阻塞。而在写路径而不是读路径上执行远程访问可以隐藏这种延迟,因为远程写不会暂停执行。此外,这样的设计也带来了进一步优化的空间,可以对写操作调度、组合,有效地使用互连带宽,同时不违反内存模型
依赖主动式远程存储的发布-订阅模型的主要挑战包含以下两点:应由哪个 GPU 接收数据,以及应该何时传输存储。为此,GPS 提供了一系列架构增强,维护订阅信息,旨在协调主动式 GPU 间通信以实现高性能,仅向需要的 GPU 传输数据,在使用过程中实现本地访问;这些是 GPS 背后的关键创新。
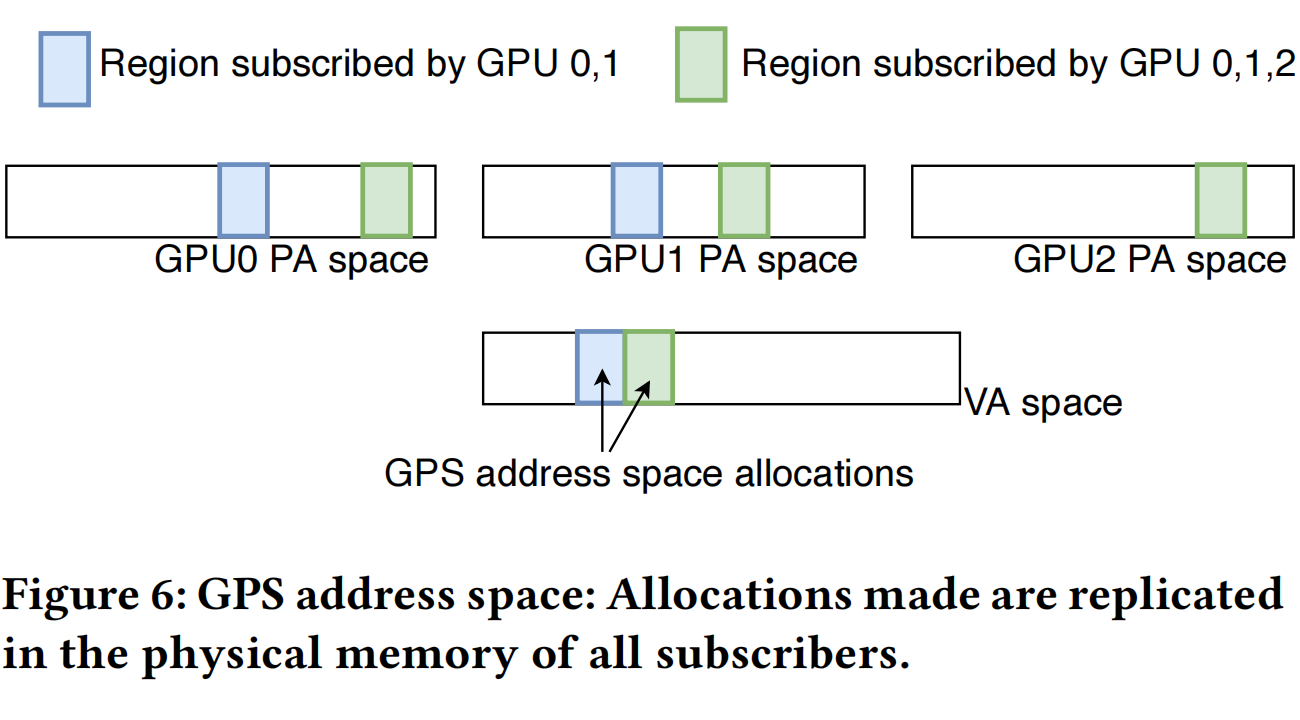
GPS 的设计目标是不破坏与 GPU 编程模型、内存一致性模型的向后兼容性,同时提供一致的性能增益;GPS 可以轻松被集成到应用程序中,只需极少的代码或概念更改。如 Figure 6 所示,GPS 扩展了传统多 GPU 共享虚拟地址空间,使 GPS 可以通过简单、直观的 API 集成到其应用程序中;只需对分配和订阅管理进行微小的更改,不需要修改为 UM 编写的 GPU 内核,很容易集成到现有的多 GPU 编程框架上。在 GPS 地址空间中的分配在所有订阅 GPU 的物理内存中都有本地副本,它与原先编程的语法相同,但底层行为不同:GPS 会拦截每个读写操作并将副本转发给每个订户的本地副本;读操作可以在完全本地带宽下执行,无需消耗互连带宽。
GPS 提供手动和自动机制来管理页面订阅。GPS 允许用户通过订阅/取消订阅 API 显式指定订阅信息,也可以通过以下两种方式之一执行自动管理:
- 默认情况下订阅,即不分青红皂白地全部订阅,然后是取消订阅阶段。
- 默认情况下不订阅,即 GPU 仅在向某个页面发出第一个读取请求时才订阅该页面。
一旦 GPS 捕获到共享者信息,共享者信息就会反馈到用于协调 GPU 间通信的订阅跟踪机制中。订阅是两种机制对 GPS 的提示,而不是正确执行应用程序的功能要求。如果 GPU 向它不是订户的页面发出加载,它不会出错;对远程 GPU 执行点对点加载会造成性能损失,但不会破坏功能正确性。
此外,GPS 在将存储操作转发到其他 GPU 之前,会主动合并到 GPS 页。这节省了宝贵的 GPU 间带宽。对于作用域访问,像传统 GPU 那样简单地处理它们。因为 GPU 内存模型只要求在执行作用域同步(如内存围栏)时,其他 GPU 可以看到写操作,所以所有作用域访问都被发送到单个一致性点并在那里执行;仅在多 GPU 上并发启动的 grid 需要通过内存显式同步时使用。一般来说这类访问很少,所以不会带来瓶颈。对于非作用域访问,GPS 仅维护必需的读写排序行为,使得同一 GPU 到同一地址的读写以相同的顺序到达。
在软件接口上,GPS 提供了 cudaMallocGPS 接口用于内存分配;它是 cudaMalloc 的代替,在 GPS 虚拟地址空间中分配内存,并在至少一个 GPU 中使用物理备份。在分配时可以传递一个可选参数,以指示将为该区域显式管理订阅;否则,GPS 将执行自动订阅管理。对应的空间使用 cudaFree 释放。此外也提供了 cuMemAdvise 接口用于内存订阅提示,接受 CU_MEM_ADVISE_GPS_SUBSCRIBE 参数以手动订阅或 CU_MEM_ADVISE_GPS_UNSUBSCRIBE 取消订阅。GPS 还可以通过 cuGPSTrackingStart 和 cuGPSTrackingStop 进行自动分析并订阅,这一分析过程不需要精确以保持正确性:GPU 仍可以访问未订阅的页面,但这样的访问将以较低的性能执行。
以下是一个可以跑在 GPS 空间的矩阵向量乘核函数示例,可以看到与普通的核函数没有任何区别。
1
2
3
4
5
6
7
__global__ void mvmul(float *mat, float *invec, float *outvec /* ... */) {
/* ... */
for (int i = 0; i < mat_dim; ++i)
sum += mat[tid * mat_dim + i] * invec[i];
outvec[tid] = sum;
/* ... */
}
以下是一个使用 GPS 并开启自动分析的示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
cudaMallocGPS(&mat, mat_dim *mat_dim_size);
cudaMallocGPS(&vec1, mat_dim_size);
cudaMallocGPS(&vec2, mat_dim_size);
cudaMemset(vec2, 0, mat_dim_size);
for (int iter = 0; iter < MAX_ITER; ++iter) {
if (iter == 0)
cuGPSTrackingStart();
for (int device = 0; device < num_devices; ++device) {
cudaSetDevice(device);
mvmul<<<num_blocks, num_threads, stream[device]>>>(mat, vec1,
vec2 /* ... */);
mvmul<<<num_blocks, num_threads, stream[device]>>>(mat, vec2,
vec1 /* ... */);
}
if (iter == 0)
cuGPSTrackingStop();
}
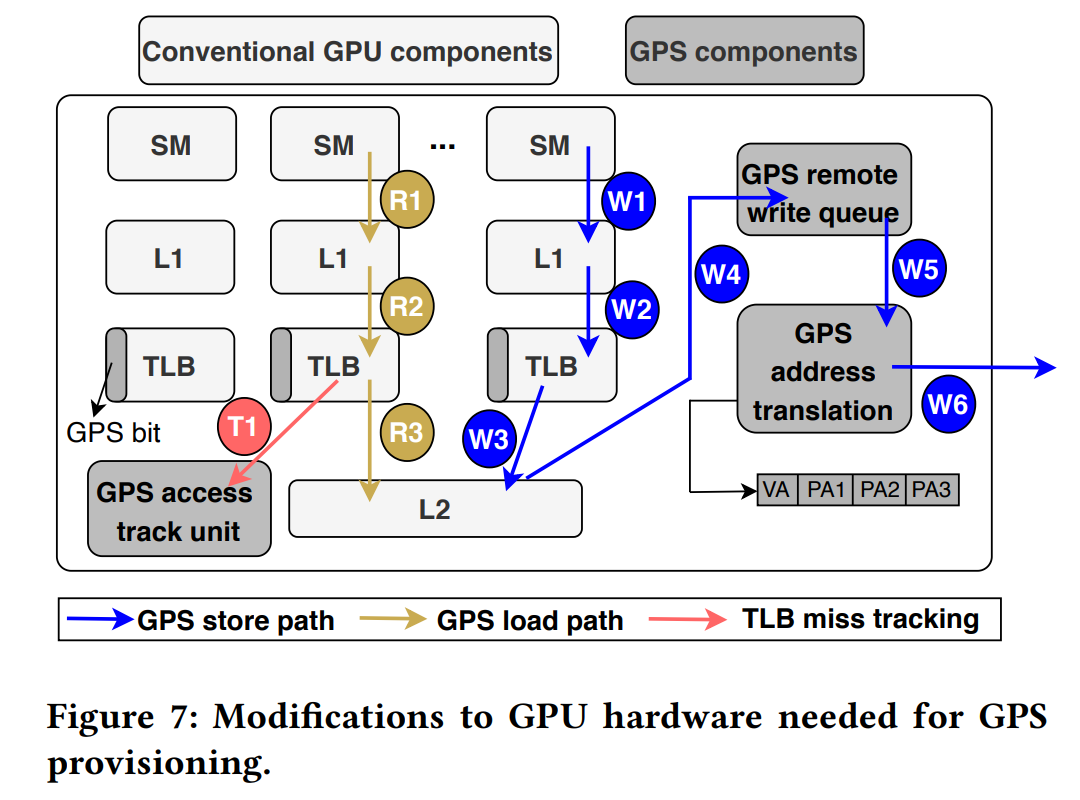
作者讨论了一种可能的 GPS 硬件实现,如 Figure 7 所示。他们在 GPU 页表条目(PTE)中增加了一位,以指示虚拟内存页是否是 GPS 页;同时增加一个新的硬件单元,负责将写操作传播到订阅了特定页面的 GPU。GPS 必须支持以下基本内存操作:传统的加载、存储和原子操作;GPS 加载;GPS 存储和原子操作。GPS 硬件单元和扩展包含页表支持、合并远程写、GPS 地址转换模块以及访问跟踪单元(用于 Profile)。
实验验证
作者基于 NVAS(NVIDIA Architectural Simulator)进行修改,该模拟器为 NV 内部模拟器,在 SASS 级别进行驱动。同时,作者在实际硬件上使用工具 NVBit,跟踪包含 CUDAAPI 事件、GPU 内核指令、访问的内存地址等,以获得最真实的估计。同时也使用了一系列具有代表性的应用用于测试,见下表。
| Application | Description | Predominant Communication Pattern |
|---|---|---|
| Jacobi | Iterative algorithm that solves a diagonally dominant system of linear equations | Peer-to-peer |
| Pagerank | Algorithm used by Google Search to rank web pages in their search engine results | Peer-to-Peer |
| SSSP | Shortest path computation between every pair of vertices in a graph | Many-to-many |
| ALS | Matrix factorization algorithm | All-to-all |
| CT | Model Based Iterative Reconstruction algorithm used in CT imaging | All-to-all |
| B2rEqwp | 3D earthquake wave-propogation model simulation using 4-order finite difference method | Peer-to-peer |
| Diffusion | A multi-GPU implementation of 3D Heat Equation and inviscid Burgers’ Equation | Peer-to-peer |
| Hit | Simulating Homogeneous Isotropic Turbulence by solving Navier-Stokes equations in 3D | Peer-to-peer |
Figure 8 展示了 GPS 在 4 张 GPU 的系统上可以达到的性能。
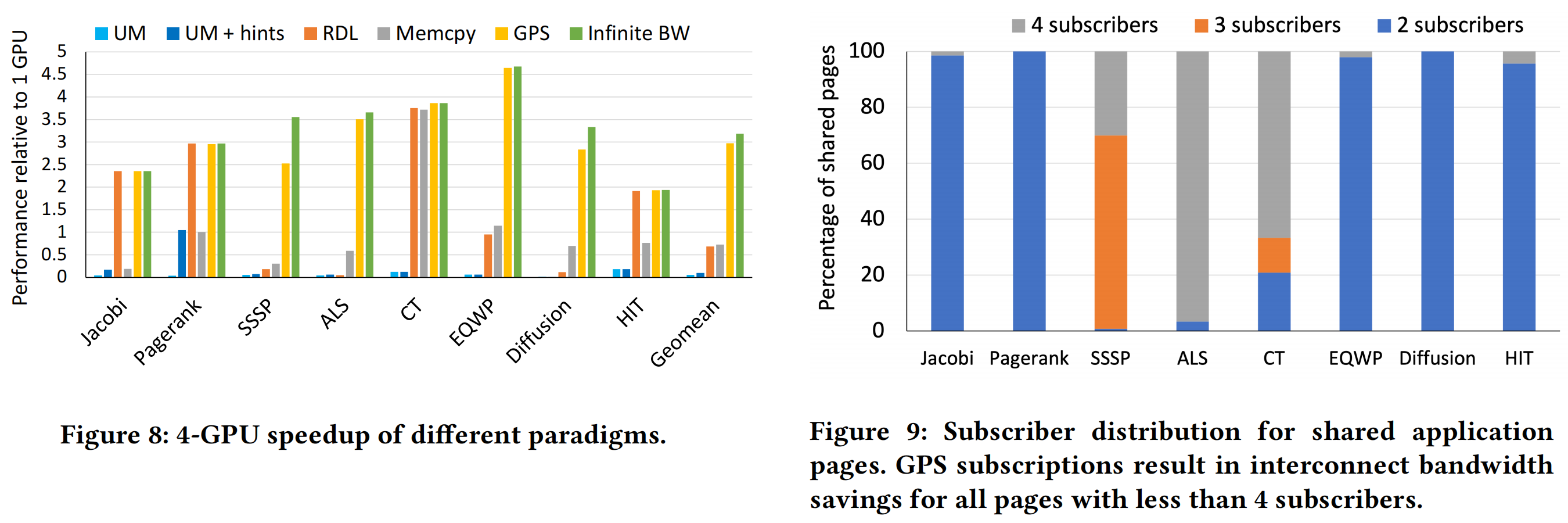
Figure 9、Figure 10 表明 GPS 的合并写操作有效地节约了宝贵的互联带宽。
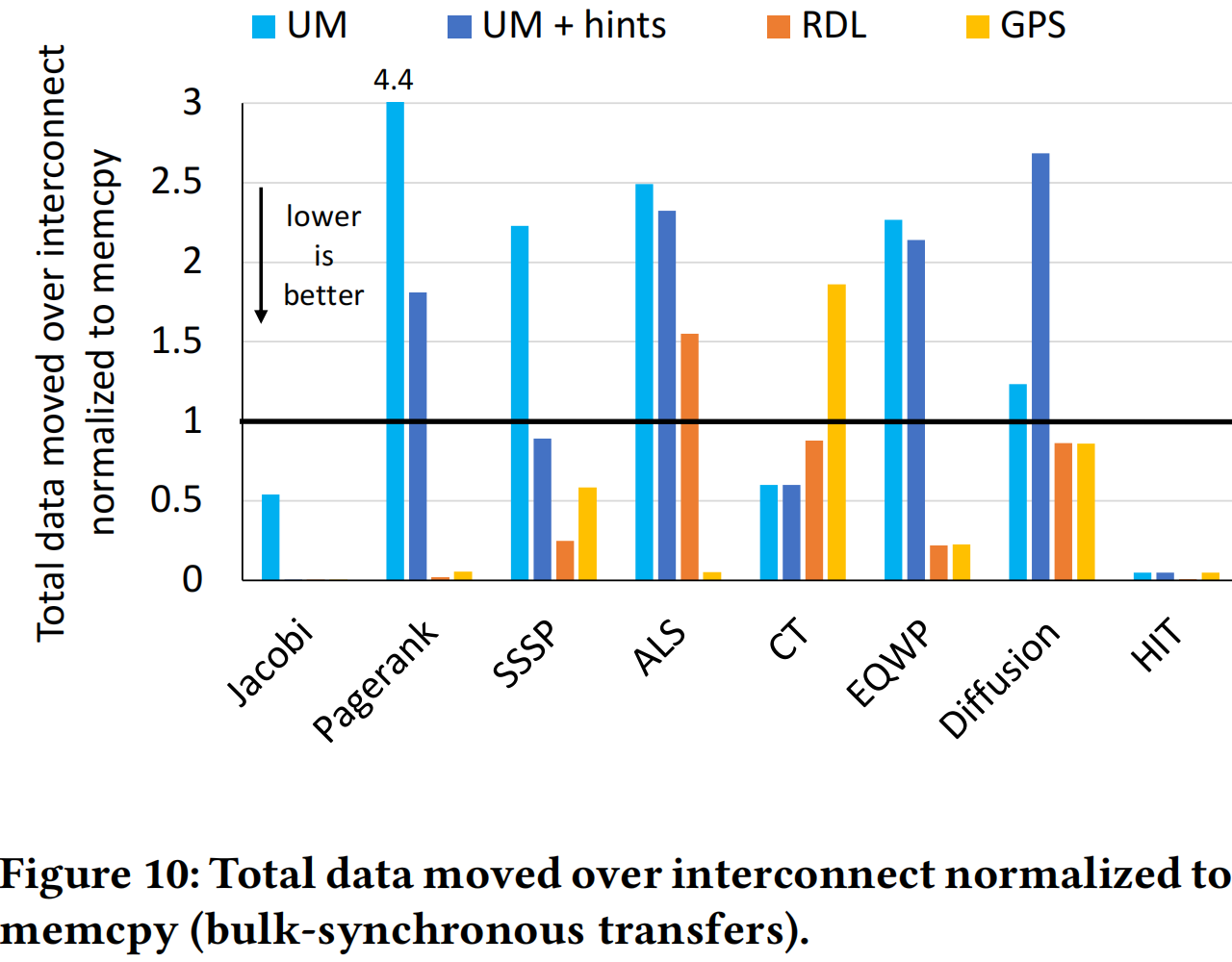
Figure 11 通过对照的形式展示了订阅机制对于 GPS 的优化效果。
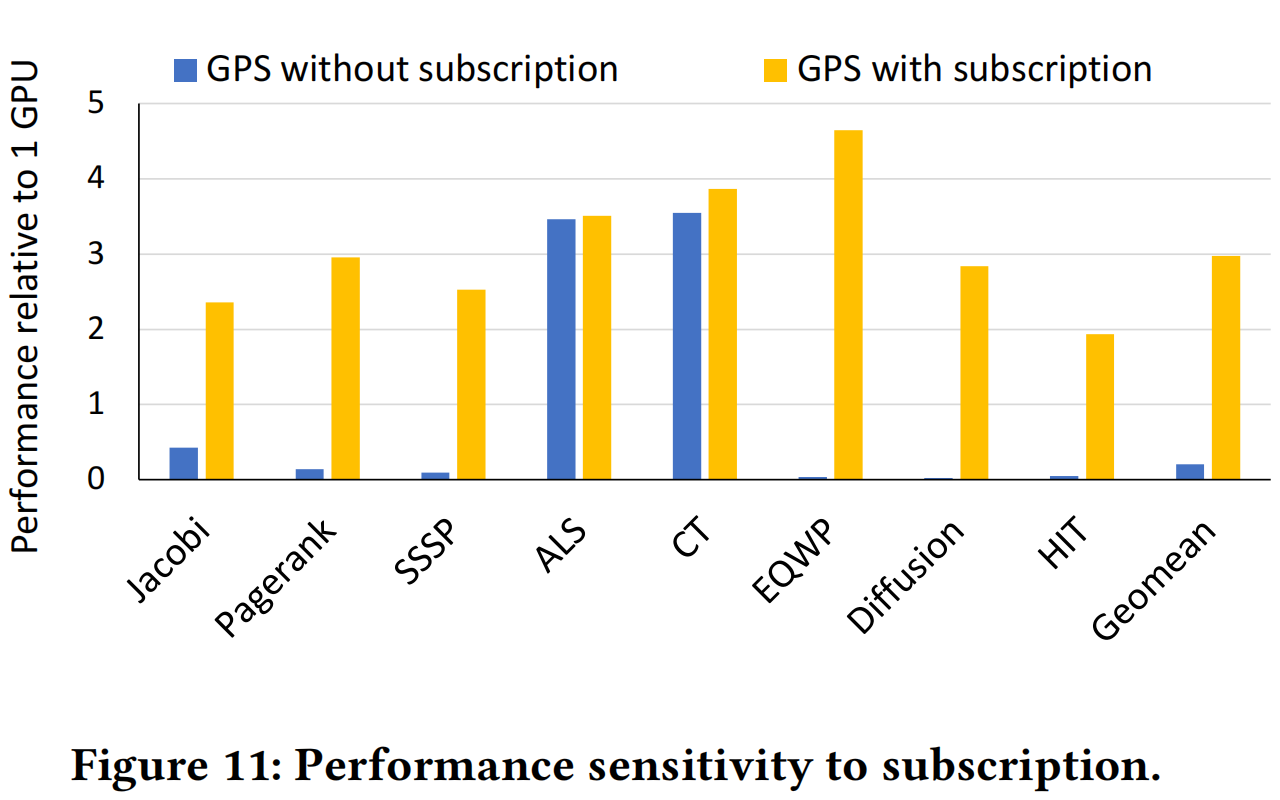
Figure 12 展示了 GPS 在一个 16 张 GPU 的系统上可以达到的性能,说明 GPS 有较好的可扩展性。
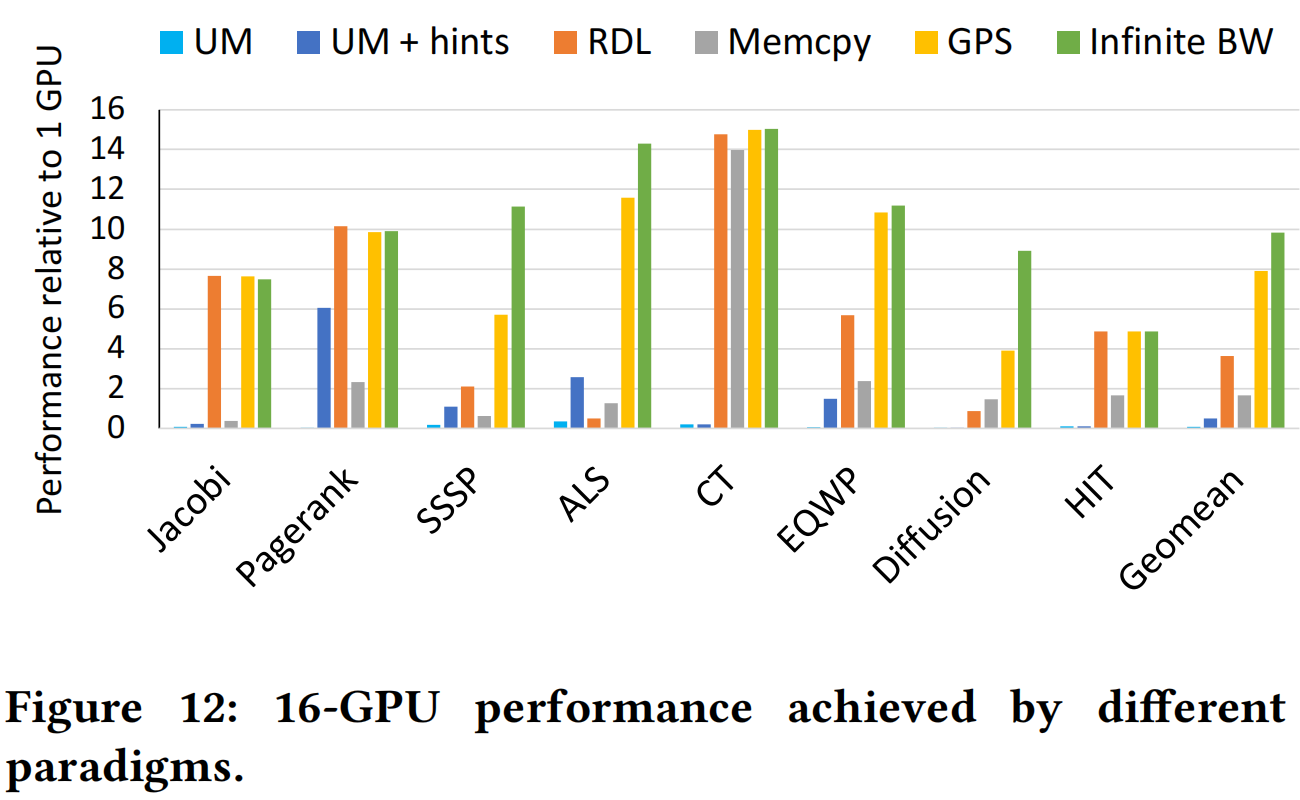
Figure 13 说明与现有的手段相比,GPS 有效缓解了互联带宽瓶颈,能在大部分情况下逼近理论性能上界。
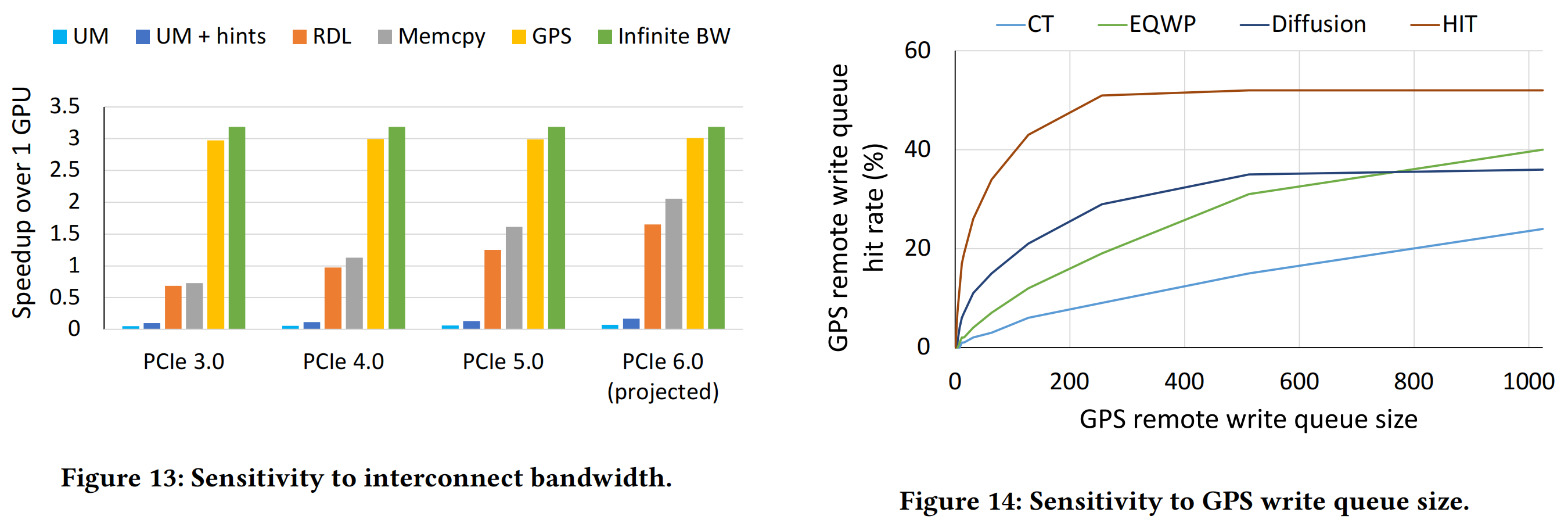
Figure 14 显示了写队列长度对于 GPS 的影响。
总结与启示
GPS是一种全新的软硬件共同设计的多 GPU 内存管理系统扩展,通过发布-订阅模式提高多 GPU 系统性能。GPS 有简单直观的编程模型扩展,可以自然地被集成到应用程序中,同时提供了显著的性能改进,大大领先于其他多 GPU 编程模型。当然 GPS 也存在一定局限性,例如其订阅以页(64KB)为单位,即使只有一位更新,也需要传输整页;通常以缓存块为粒度进行互联,导致传输不必要的字节;写合并技术可能不会合并时间上间隔较远的操作导致效率下降。
GPS 也给人非常好的启发,因为发布-订阅机制原用于软件工程领域的一些设计,而在面对多卡编程这样一个硬件领域的老大难问题时却发挥出了出人意料的效果;我们在进行一些软硬件架构设计时也可以相互借鉴。此外,这篇文章给出了非常充分、扎实的实验数据,非常直观地展示了 GPS 预期能够得到的收益,讨论与对比也很给人以思考。总的来说,重要的问题、灵性的设计与扎实的实验并重,不愧是一篇能够获得最佳论文提名的论文。
Related posts