我的ASC决赛复盘:冒险、失误与翻车
post on 19 May 2021 about 10962words require 37min
CC BY 4.0 (除特别声明或转载文章外)
如果这些文字帮助到你,可以请我喝一杯咖啡~
忙完了毕业论文答辩之后,终于有时间能够静下心来写这样一篇文章。虽然比赛结果还行,但是回顾整个决赛过程,几乎没有一个环节可以说做得非常好的。
5 月 8 日,装机 Day 1
5 月 8 日一早,一行人抱着我们的设备进入赛场,包括了提前做好的几个版本的系统盘(Centos7.6、Centos8.0 以及 ASC19 决赛用过的系统盘镜像)、若干企业级 PCIE SSD、A100 显卡、插线版、螺丝刀及三盒搭配的刀头。八台浪潮 5280M6 已经摆放在我们的机架上,一切都蓄势待发。

我们第一件事就是进 BIOS 看机器配置,但是迎面而来的志强铂金 8358让我们立觉不妙(以往决赛提供的都是金牌处理器)。果然,官网上查到的信息印证了我们的直觉。我们现场算了一下,单 Socket 双精度算力接近 3Tflops,已经抵上小半张 V100 显卡了。于此同时,更为恐怖的是高达 250W 的 TDP,这意味着我们赛前设计的六机八卡方案几乎绝对不可行,即使使用四机八卡的配置也要疯狂压住功耗。
打开机箱后的迎面而来的 raid 卡则更让我们心里一凉,这意味着我们提前准备的系统并不能直接插盘启动。虽然不抱希望,我们还是把一块装好了我们自己系统盘的硬盘托架插进了机器,经过了一翻折腾,果然启动不了。这时候接到赛会通知,我和轩轩要去后台领取机器配置表、硬件安装说明、团队应用赛题等一些东西。说明书上说这个服务器最多可以接三张显卡,但是赛会只提供了一个双卡的示例。
等到我出来的时候,组委会开始清理场上人员,只要是戴了观摩队员牌子的人一律给你请到场下(之前并没有说装机环节观摩队不能在场上)。不过队员们似乎已经找到绕过 raid 卡进入系统的方法,赛前我们觉得最容易出现问题的 IB 驱动也很给力的起起来了,目前来看除了 raid 卡让我们吓出冷汗之外装机进度还算顺利,只留我们六个带着参赛队员牌的人完全没有问题。到中午的时候,我们起了六台机器,并在六号机上运行我们的一键部署脚本;我就在边上改几台机器的路由和 IPMI 接口的 IP。
截至目前为止,一切的一切还在按照我们赛前的时间线进行:中午之前起起来所有的机器并开始部署软件环境,下午就可以进行节点体检,顺利的话还能跑一些 PRESTO 和 QuEST 的测试。节点体检的结果显示,三号机四号机的 CPU 体质比一号机二号机好一些,不过在合理误差内,没有大问题。三点钟左右的时候跑完了osu,我们的 IB 网也没有问题。终于轮到我来测一下 QuEST 赛题的情况:初赛 random 算例单卡 8.24s、单机双卡 72s、双机四卡 50s。由于来比赛之前已经预期 PCIe4.0 带宽远低于我初赛阶段用于优化的 NVLink,此时我并没有意识到这个运行时间有什么问题,就是觉得是因为跨 PCIe 通信开销过大。于是机时让给 PRESTO、AI 赛题负责的同学。尤其是 PRESTO,在这么强的 CPU 上的性能我们需要重新估计一下。
五点半的时候,三号机四号机的显卡空了出来,我想试一下跨节点通信对我的多卡 QuEST 的影响,便在上面各起了一个进程,每个进程使用一张卡。测试的结果让人大跌眼镜:11s,这意味着跨节点通信比节点内通信还要快得多!我马上把这一发现和大家说了。终端输入一个 nvidia-smi topo -m看一下,两张卡是接在不同 CPU 上的,我猜测跨 CPU 的 GPU P2P 通信走了内存中转。为验证这一现象不是节点本身的问题,我们把正在运行的 AI 赛题咔掉,在每个节点上都运行了程序,结果都是这样。
怎么办?我们让家振去重测一下结点间的带宽和显卡的 P2P 带宽(用 NVIDIA 自己的 sample 代码),与此同时我把四号机拆了下来,重新安装两张显卡。不得不说,非赛会推荐的显卡安装真的非常难走线,要把显卡前面的横杆拆掉;一张显卡的电源线还要以一个非常妖娆的姿势从卡的下面扭上来(因为主板供电接口在这张卡的正下方)。

如上图,浪潮推荐的显卡安装方式是上面两个槽,如果我想装在图上两个红圈的地方,就要把原来上面的 IB 卡调整位置,而且还要注意显卡电源供电接口的位置。六点三十分,我改过显卡安装位置的四号机重新点亮,测试得 random 算例一机两卡 28s。看来跨 socket 可能是影响显卡 P2P 速率的原因,但是仍然比跨节点通信要慢,还有其他原因。
六点四十,我们没有搞清楚节点内通信慢的原因(家振测试的结果也支持我的发现),不过又想了一种新的改装方案:既然我们已经把两张显卡挂在同一个 CPU 上了,不如再把 IB 网卡也挂在同一个 CPU 上,这样我们后面跑 Linpack 的时候就可以直接把另外一个 CPU 压到一个很低的功耗。但是,原先我对四号机的改装方法中是把两张显卡接在 CPU0 上,由于机箱的结构限制,没有办法再把 IB 网卡接在 CPU0 上。经过对这个机器主板和接线的仔细观察,我们发现中间一个 PCIe 扩展卡背后伸出四根很粗壮的线,分别走两边连到了两个 CPU Socket 附近,大胆猜测这四根线就是 PCIe 到 Socket 的连接线。换句话说,我们只要调整这四根线到 CPU 的连接位置,应该就可以按照我们想的方案一样,把两张显卡和 IB 网卡接到 CPU1 上了!但是此时遇到了新的问题:这四根线的长度是定制的,两长两短,刚好能够接到原先的 CPU 上;我们想改接的话原来的线不是过长就是过短了。

最后的解决方案是,从两个 CPU Socket 上的内存插槽中间走线(需要拆卸、调整一些内存条的位置)。即使找到了这样一个巧妙的位置,理线工作仍然是个地狱:既要找到一块足够大的地方放下过长的线,又不能挡住 CPU 的风道。七点二十分,我们重新改线的二号机点亮了。我们松了一口气,能点亮至少说明把四根线修改接口之后不会影响系统的基本功能。但是进了系统之后我们再次血压拉满:其中一张 A100 显卡工作在 PCIe x8 模式下,而非原先的 PCIe x16 模式!这说明要么我们接线没接紧,要么接线的插口还有什么别的限制,或是这个 CPU 本身就不能同时带动三个 x16 状态下的设备。
我们再次把二号机从机架上拉出来,观察接线有没有什么别的问题。我们摇了一下我们的接线,应当都是接紧的;主板上这几个接口附近也没有什么明显的标识。我大着胆子把 CPU1 的两根接线交换了一下,七点四十分我们重新进入二号机的系统,显卡和网卡终于工作在正常的模式下,所有人都长喘出一口气,改装成功了!
但是紧接着的一个事实让我们的血压再次拉满(这已经是今天不知道第多少次了):八点钟赛会就要全场下电了。我们观察了一下全场的队伍,基本上这个时候都已经完成了对各自机器的组装和调整;入口处的一个学校似乎组了 1TB 内存的胖节点,他们拆下来的占位条堆成了一座小山。如果说我们在午餐前就点亮了所有机器的系统(很可能是场上进度最快的学校),那我们现在的处境很可能是全场最糟的:还有至少三台机器需要重新改装内部走线,并且节点间的带宽也需要重新测试;计划中原定的 HPL、HPCG、AI 赛题都没有测试。
为了最大化节省明天白天的时间用于测试,我们决定在断电之后把所有机器的硬件改装做完。七点五十五分,我们把所有机器关机,并把二号机之外的其他机器机架上拆下来。八点整,我们的「星河姬」玉体横陈,也吸引了很多别的队伍围观;闻声赶来的赛会希望我们尽快离开,但是我们则希望能把机器装好(因为确实没有规则说下电之后不能调整机器或是留在赛场)。结果是,我们吃了一发赛会的警告,只好把衣衫不整的星河姬先抱到我们的座位后方,并把她的隐私部位——四张已经拆下来的 A100 显卡带走。
总之第一天的结尾,我们落到一个非常狼狈的境地:所有的机器都需要重新装,很多赛题都没有测试,而且我们甚至还要手动把四张总价二十六万的显卡带回酒店。而且,晚上对机器的改装太急,所有的人都没有吃晚饭,还有几个队员没有搞清楚情况的。大家去金拱门匆匆点了些东西,然后带到我的房间,一边啃汉堡一边开总结会。
5 月 9 日,装机 Day 2
第二天一早,大家再次进入赛场,手上土豪金色的 A100 帮我们吸引了很多注意。但是我们已经顾不上太多,今天我们的压力比昨天还要大得多。
由于我已经改了两台机器,对改装的流程比较熟悉,昨晚我们决定赛场上分成两组流水线作业:我带景润、正曦三个人改装一号机、三号机、四号机;轩轩带家振、炜乐先把软件盘重新装在昨天已经改好的二号机上运行一些测试,再把我们这边改好的机器上架检查。
昨晚的骚动影响还没有褪去,有很多学校的人跑到我们这看我们在干什么,于是我们三个人把机器搬到了台后改装,不得不说是个很正确的决定。由于夜里已经在脑海中无数次演练过早上的装机环节,早上大家的配合非常流畅,十点钟的时候四台机器就已经全部改装完毕并成功进入系统。唯一有点失手的是在装三号机的时候,有两根线非常难走,以至于我和景润的手都被锋利的侧板划了口子(观摩队的同学带了创口贴,血也万幸没有流到主板上,我们把侧板上的血用纸仔细擦干净了)。轩轩那边也验证了,显卡的 PCIe 模式确实是因为接线顺序。
终于可以喘口气,于是我跑去休息室吃了一些蛋糕,然后去看台上看别的队伍的情况(其他队员继续做昨天被打断的测试)。我们的正对面就是大清中 门 对 狙,他们昨天下午就装好了机器,似乎已经做了很多的测试,感觉相当稳。他们也拆了几台机器下来,似乎在对 IB 网卡做什么调整(赛后和他们交流,说是在测试一台机器带三张显卡的可能性)。非常恐怖的是,他们装机这两天的功耗一直非常稳的压在 3000w 附近,这让我们猜测他们有什么「自动驾驶」的手段(赛后被否认了)。我们也关注了其他几个「传统强队」的情况,大部分都和我们一样打算使用四机八卡的配置。
下午,我提前把最后的机器配置表交到赛会,似乎也是第一个交的学校。不过问题并不大,今年这颗铂金 CPU 下,应该也没有必要对自己队伍配置进行过多保密。交完配置表回来的几分钟,刚好队员们正在跑的一项测试跑完了,那我就来重新跑一下 QuEST 吧!跑的结果让我再次血压拉满,甚至有些无奈:一机两卡 random 算例在每个节点上都是 67s,退回到了最开始的水平!然而距离装机环节的结束只剩不到五个小时了,我们不能再拿后面的时间去冒险了;况且我们的 HPL 和 HPCG 都没有跑,即使找到了解决方案也必须优先腾出时间去试 HPL 和 HPCG 的最佳参数。我回到看台上,和其他人紧急讨论这个意外情况,其他队员继续去试 HPL 和 HPCG 的参数。最后决定,我们不再对机器硬件进行调整。我连回天河,希望通过软件上调整进程与显卡、节点的绑定,最大化避免节点内部两个进程的通信;光南则在我们在学校的另外两台 KNL 服务器做实验,看看是否能骗过 MPI,所有的通信都走 IB 网卡过一下。
六点钟的时候,万能的群友不知道从哪里搞到了 5280M6 的文档,发现我们改过线的那张 PCIe 扩展卡上,还有两根很细的线,分别被标注成 CLK1 和 CLK2。难道我们把两张卡挂在 CPU1 上,却读了 CPU0 的时钟信号?想想不大可能,这么严重的问题应该完全点亮不了系统才对。但是我们来不及多想,马上把四号机关机,以最快的速度调整了这两个线的接口(因为此时离断电只剩不到两个小时了,昨晚的经历让我们不敢再去试赛会的底线)。四号机点亮之后结果还是一样,虽然同节点内部通信的问题没有改善,但是至少我们没有犯时钟接错的大问题。
经历之前的风波之后,我们用于练习「开车」的时间已经非常有限。七点三十五分,我们终于完全测试好了第二天一早要跑的 HPL,预期结果在 78Tflops 附近。但是此时时间已经不够我们再去练习一次完整的 HPCG(需要大于 1800s),我们只好先跑一个十五分钟的。七点五十七分,我们算是勉强完成了所有赛题的测试,非常极限的在断电前关掉了我们的机器。
不过今天赛会管的显然不如昨天严,断电之后还有队伍在对机器大作调整,甚至把机架的侧盖整个拆了下来。说好的警告呢…
另外装机的两天我们全程拍了一个 vlog,已上传 B 站~ 对具体走线改装的部分大约在 55 秒和 1 分 30 秒的位置
5 月 10 日,比赛 Day 1
前一天晚上,赛会通知明天上场还是六个人。但是,赛前的 rulebook 上已经写了在正式比赛的两天,场上只能有五名队员,遇到问题的时候才能和 advisor 交流。于是我要对接的志愿者重新和赛会确认一下。一早传来消息,果然只能五个人。不过我们赛前已经对这种情况有预案,我的任务更多在于场上队员和场下以及留在超算中心的其他人之间的沟通。
顺带提一下我的 advisor 身份。在年初提交决赛名单的时候正好原来的指导老师杜总离职了,我们和新的指导老师广爷和黄聃老师商量了一下,今年决赛还是由老队员带队去决赛现场;而作为赛队日常训练时名义上的队长,我做这次的 advisor。当然,也有一定的风险,正式比赛环节 advisor 和其他老队员很可能只能留在看台上。不过我自己倒是没有意见,毕竟水野爱也有不上场的时候;况且我也已经大四了,让大三的同学多一些场上经验,对我们下一年的决赛也有好处(希望这里没有立下明年进不了决赛的 flag)。
早上八点钟,五个队员进入赛场,把所有机器的风扇功率开到最大,准备开跑 Linpack;我们其他几个老队员坐在正后方的看台上。白白写了一个非常有意思的 bot,从赛会官方的监控网页爬取各个队伍的功耗数据,并在爆功耗的时候推送到 Lark 上。
安利一下超算队内部沟通用的 Lark(飞书),是我们使用体验最好的协作工具。我在字节实习的时候就发现它和 Grafana 等监控软件联通很方便,同时飞书文档也比我们之前用的腾讯文档好用很多,可以直接插代码块,很适合赛场上大家同步进度;我们的答辩 ppt 也是在飞书文档上做的。

第一次跑 Linpack ,我们就很幸运地跑出了 79.04 Tflops 的好成绩,比我们前一天晚上的结果还要好一点,而且没有爆功耗。于是我们决定直接提交这次的结果,以便更早拿到其他赛题。手机也在疯狂推送其他学校爆功耗的消息,看来别的学校都已经开始跑 Linpack 了。我也顺手查了一下 Top500 榜单,我们的结果已经超过 2004 年世界第一的超算「蓝色基因」原型机了。
按照之前的安排,拿到其他赛题后(按照规则,要提交 Linpack 的结果之后才可以拿到今天其他赛题的数据)先解压 PRESTO 赛题的数据,然后负责 PRESTO 赛题的轩轩研究决赛算例,并调整之前优化的代码;其他人跑 HPCG 和团队应用。拿到赛题之后,我们发现 PRESTO 赛题提供的从「中国天眼」上扒下来的数据光压缩包都有足足 53GB。我们已经猜到决赛会有很大的算例,不过这么大的还在我们意料之外;尤其是我们提前在 Centos 上装的解压工具 tar 还是单线程的,光解压就不知道要等到猴年马月。于是场上的同学先去跑 HPCG,看台上的同学去找有没有多线程的解压工具。最后经过一番 Google,我们现场学了 lbzip2 的用法。
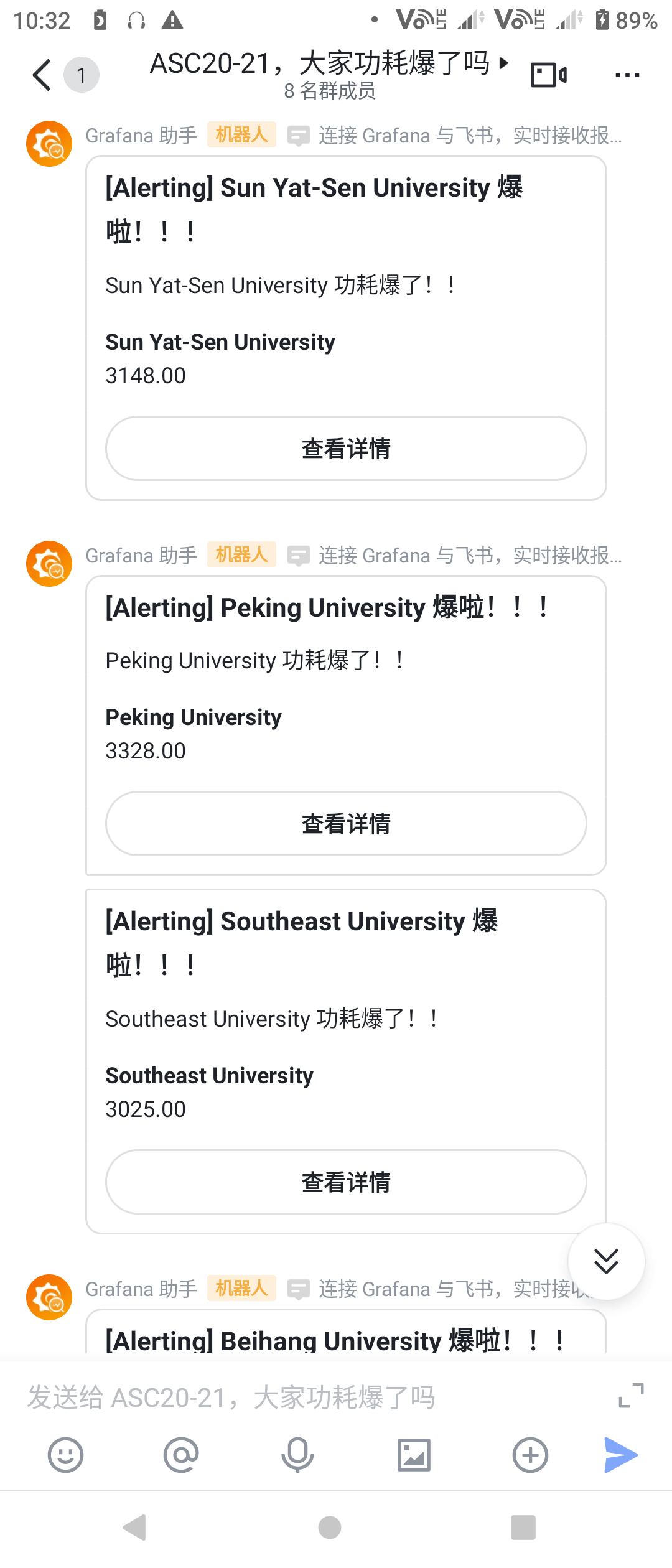
十点多的时候,我们早已跑完 HPCG,但是手机上突然推送:Sun Yat-sen University 爆啦!这让在看台上的我们吓了一跳。原来是队员们在用 pip 安装团队应用的某个依赖的时候使用全核编译了,一不留神就爆了功耗。250 瓦的 CPU,真的就是火龙啊
十一点四十的时候,赛委会那边开始有人走动,要公布早上跑 Linpack 的成绩了!因为今年决赛大家的机器配置都差不多,因此 Linpack 的排名还有很大悬念。一开始看到赛会写某个学校的成绩是 92Tflops,我们是场上的第二名,大家都高呼可惜。被超过这么多,我们猜测他们是组了四机十二卡的配置,单纯为了冲这一项的跑分来的(如果把显卡功耗压到 120w 的话确实有可能做到)。不过看那个学校的位置上完全看不出开心的迹象;也有别的学校同学去赛会那里去争论(以我在看台上的视角,几乎要吵起来了)。原来是小数点点错了,我们是第一!顿时微信群里老人家的红包横飞,我也激动地发了一条票圈。
稍微冷静下来一些之后,我们也关注了别的学校的成绩。第二名大清跑出了接近 78Tflops 的成绩,我们实际上也只是险胜;这还是我们对机器改装、把其中一块 CPU 的功率从 250W 暴力压到了 60W(此时频率甚至只有 100+MHz)下的结果,看来他们还有着非常强的控功耗的技术。
紧接着我又意识到,赛前的安排出了大问题:PRESTO 这边只有轩轩在负责,第一天剩下的压力全在轩轩身上了。赛前我们有向赛会发邮件咨询过 PRESTO 软件版本的问题,赛会这样回复:「关于 PRESTO 和 Python 版本没有限制,参赛队可以选择性能最优版本。」然而事实上最后能跑通的只有 PRESTO-3 版本,而我们之前的优化工作都是在 PRESTO-2 上做的,需要现场改很多代码。
到了结束的时候,我们的 PRESTO 赛题跑了 10/12 个点,只完整处理完了第一组数据,已经是非常全力的发挥了。除了 HPL 之外,今天的成绩要明早才能公布。散场的时候,很多学校都来我们这边看我们的机器,想知道我们是不是对机器做了什么改造;不过我们的接线从外面也并看不出来,所以问题不大。
5 月 11 日,比赛 Day 2
比赛第二天的任务非常重,个个都不是好啃的骨头。按照之前的计划,我们应该上来就把最吃显卡算力的 AI 赛题赛题跑掉;在这段时间,我和景润连回天河,分别把赛会提供的魔改版 QuEST(针对决赛增加了几个魔改的电路门)加进我们俩之前写的 GPU/CPU 版本;然后剩下的人 All in 神秘应用,毕竟 ASC19 的时候我们就是靠着神秘应用逆风翻盘的,平时的训练也主要针对神秘应用进行训练。
然而比赛就是比赛,永远不会按照你预先写的剧本进行。一早我们拿到 AI 赛题的模型,发现赛会居然提供的是 ALBERT-xxlarge(这次决赛和以往不同,主办方说必须使用提供的 Dataset 和 Pretrained Model,导致决赛发挥余地有限。同时,赛会给的 Baseline 用的是 BERT-Large,我们下意识地以为现场也会是 BERT-Large,准备的时候就一直调试 BERT-Large 模型)。虽然之前也有准备 ALBERT 的代码,但是因为没怎么跑过,现场跑出来的结果就和瞎猜一样,现场 debug 也发现不了自己的训练脚本问题出在哪。
QuEST 赛题这边的问题也一样。赛会在我问比赛版本的时候有意无意的回避了 QuEST 赛题的版本问题,一拿到代码果然是在 QuEST-3 上的魔改,然而初赛阶段却规定必须用 QuEST-2 去跑!不过我也有准备,提前把 QuEST-2 和 QuEST-3 的主要更新点搞明白了,赛场上我要做的就是把 QuEST-3 接口中的 Unitary 矩阵重新转换成 QuEST-2 中的存储格式,这样就能接入我写的基于 QuEST-2 的多 GPU 后端了(还要补全 QuEST-3 新增的一些 API),如果对这个软件很熟悉的话难度其实没有很高,主要是心要细,改的时候不能出问题。
赛会提供的算例也是非常坑,一共有一个 34 量子比特的算例,三个 35 量子比特的算例,还有一个 22 量子比特的算例,但是有上万个量子门,搞人心态。赛前我看到一台机器的默认配置内存是 512GB,便断定赛会不会出超过 34 量子比特的算例,否则如果不做内存压缩的话连单节点和双节点的 baseline 都跑不了(需要 1TB 内存)!事实证明真的不能把赛会当成好人,他们真的就是抱着让所有人都跑不了的心态出的题。因此我做过内存压缩的 GPU 版本只能跑算例一(34 量子比特)和算例四(22 量子比特),剩下三个算例要丢到 CPU 上去跑。
赛会也公布了前一天的得分情况,大清在除了 Linpack 的所有赛题上都拿到了第一,而我们在 Linpack 上也并没有和他们拉开差距,总体得分比他们少了五六分,恐怖如斯。
上午十点钟,原以为工作量最大的 QuEST GPU 版本居然是我们今天第一次得分。由于之前测得节点内部通信的问题,我们的进程到节点是一个非常古怪的「12213443」的绑定方法,在这种绑定方法下大部分通信流量都是走 IB 网。算例一必须八卡去跑,跑了 33 秒;算例四则在两卡下能跑到 13 秒。CPU 版本那边则出了大问题:因为没有写内存压缩,我们必须在全部四个节点上才能跑 35 比特的算例。然而跑了十分钟我们的监控根本没有看到通信的流量!无奈我们只好掏出赛会的魔改代码,希望能跑 baseline,但是用 CPU 想跑出一个算例我估算也要大半个小时,场上队员还要保持精力去控制机器的功耗,一不留神就会爆功耗。
我们现在就是非常后悔,如果我们能够提前把内存加到每个节点 768GB 内存(因为我们对机器的改装需要走内存条走线,不能把内存插满到 1TB),也不用像这样被动,每次跑都要全部节点了。神秘应用那边的环境遇到了非常大的困难,有的软件版本依赖过高也跑不了,过低也不行,我们只好每个人(在天河上)试不同的版本。
到下午大概一点多的时候,我们绝望地发现,除了之前跑通的 QuEST 的两个算例,我们在所有赛题上都进入了绝境。我们决定直接跑 AI 赛题的 baseline,中间还要穿插编译神秘应用的依赖。然而赛会提供的 baseline 也有大大小小的问题,模型始终不收敛。
一直到下午快四点,我们孤注一掷,决定只用三分之一的数据集训练十分钟,至少要有一个能交的结果。不过 ALBERT 模型还是非常强大的,这么搞居然也能在 Dev 数据集达到 80% 的准确度。
中间轩轩去抽了个签,手很臭,居然抽到明天第一个答辩。鉴于场上队员已经濒临崩溃的心理状态,我们决定 AI 赛题之后去跑神秘应用,给大家一个喘息的时间(或者说放弃 QuEST 的 CPU 版本了)。结果证明我们再次犯了错。虽然我们成功跑起了神秘应用,但是从应用输出的 log 来看,在我们的机器上要跑完一个算例至少要十二个小时(赛后复盘的时候发现这个应用的瓶颈主要在 IO 上,而我们这次没有组 raid,机器的 IO 性能拉了,临时组内存盘也是杯水车薪)。五点多的时候终于能跑 QuEST,然而直到比赛结束我们也没能再跑出一个算例来。
在看台上的压力已经如此紧迫,场上队员的压力更是不用多说。当比赛正式结束,我下到我们的机位时候,有的队员的眼睛都已经红了。所有的人都没吃中饭和晚饭,情绪也很低落,然而我们还要把所有的机器都复原,交给浪潮的人验收之后才能离场。
拆机前我和「星河一号」最后拍了一张照,照片上完全看不出来当时的心境。不管怎样,属于我的 ASC 已经正式画上句号了(答辩环节我虽然可以在场但是也不能过多发言),而且我们至少还破了个记录,我还作为领队被采访上了一次推送,即使有遗憾,但也并不是毫无亮点。

大家把机器装得差不多的时候,我打起精神,跑去和别的学校社交,毕竟比赛就是比赛而已;我和北航的同学正好在同一个组实习,挺好的面基机会不要错过了。我们聊了各种赛题的情况,还介绍了我们对机器的详细改装方法。最后我也去大清那边问了他们 QuEST 赛题的情况,因为赛前就听说他们这题做的非常好,果然比我们快了三倍多。
5 月 12 日,答辩 + 颁奖
由于前一天轩轩手特别臭,我们很不幸的抽中了一号签去答辩。我们规定的答辩时间是七点四十五,而按照比赛的规则,PPT 需要提前四十五分钟送到会场。六点四十分,大家的早饭稀稀拉拉还没有吃完,我就先坐上了去会场的小巴,把我们的 PPT 先送过去。队员们上了七点十五的那一班车,七点二十五的时候人就都齐了。七点四十分,我们六个人进入答辩室。
再次吐槽一下让人有点晕的规则:装机的时候可以六个人,正式比赛只能五个人,答辩又要六个人
刚进到答辩室,就看到屏幕上的专家列表里赫然有 Jack Dongarra 老人家。这让我超级激动,因为我的毕业设计就是在做 Linpack 相关的工作,其中有相当大的工作都引用了这位大佬的!我拿出手机,拍下了这一(对我来说)历史性的一幕。

因为已经和黄聃老师一起做过预演,大家很顺溜的完成了英文展示和答辩。我还记得 Jack 问我们,「Did you modify the HPL codes?」轩轩回答:「No, we used the binary from NVIDIA.」展示和问问题的时间都恰到好处,不过结束离场的时候有点点小尴尬,我就拍了一两下手,然后现场的专家们就和我们一起鼓掌,答辩室内充满了快活的空气。
出了答辩室,意味着长达五天的赛程终于画上终点了。所有的人都疲惫不堪(身体上、精神上),大家都回酒店,补觉到中午十二点,然后一起在海底捞大吃一顿。工作日海底捞人不多,于是我们享受了非常周到的服务。
颁奖典礼在下午三点开始,两点五十分的时候对接的志愿者把领奖的顺序发给了我们。我们竟然是一等奖最后一个上台领奖的,那么说明我们竟然拿了第三!本来大家已经很悲观,觉得今年表现这么差,搞不好要击穿中大参赛历史(12 年~17 年都是第四,18 年第六,19 年第三)的下限了,没想到居然追平了去年的纪录。一等奖名单里还缺了大清和坐在我们前面的暨大,看来最后的赢家就要在他们之间产生了。昨天和大清那边交流过,他们赛场上放弃了整道 AI 题,因此虽然大清整体实力非常强,但是也不是无懈可击的。不过怎么说呢,虽然我们也被宣传成「传统强队」,但真正的强队有且只有一支,中大只能算个「奖杯守门员」罢了!

终于开始颁奖典礼,主持人介绍到场嘉宾的时候,我们发现卢总竟然也来了颁奖仪式;到我们上台领奖的时候,卢总还和我招了一下手(上台的同学里只有我之前见过卢总)。终于轮到冠亚军的归属,主持人故意卖了个关子,然后才报出亚军是清华。全场掌声雷动,不过很大一部分都是给我们前面的暨大的同学的。当然,有一说一,清华的实力还是非常强,虽然我们的名次只差了一名,赛场上还是能够明显感受到两边的差距(甚至把我们的队员虐哭了),并且他们在除了 Linpack 和 AI 之外的所有题目都拿到了第一,恐怖如斯!
亚军的颁奖是卢总来的,卢总的咖位很高,是我们太菜了(笑)。不过赛后我们也和卢总一起拍了合照。再之后,我们作为 Linpack 奖得主,和冠亚军一起接受「东方媒体」的采访。作为队里公认会「说话」的人,我再次被大家推出来。除了媒体群访之外,还有一个专访。记得被问了这样一个问题,认为我们国家超算领域处于什么现状,我们未来要为超算领域怎么样?我回答问题的时候满脑子群友的格局表情包,其结果就是站在国家角度发表了一通讲话。

赛后我们很光荣的上了新闻联播,但幸好这一段被剪掉了,不然美国对广州超算中心的制裁估计永远不会结束了(笑)

特朗普或者拜登不看深圳卫视的吧
奖也写错了
晚上我们和暨大的队员们一起在「南山必胜客」(深圳南山区的一家比萨 🍕 店)约饭,顺便交流各个赛题的情况。暨大这次的表现真的是非常稳,所有赛题都认认真真去跑了,QuEST 即使是 CPU 版本也跑了很多算例;而且他们也不像我们一样有经验丰富的老队员带队。我们都心服口服。
后记
再次回看一下整场比赛,我们无论是从赛题优化、预先准备还是现场发挥都出现了很严重的问题。今年是我们离奖杯最近的一年,也是我们离奖杯最远的一年;期待以后的队员能满怀敬意地对奖杯发起挑战,让我能看到中大捧杯的那一天。最后还是以爱酱不上场的这首歌结尾一下:
to be brave そう胸の flame
眼前有剑 心中有火焰
后后记
今天(5 月 19 日)我们收到了大清快递过来的礼物(老队员前几届比赛就已经认识了),是他们设计的一些贴纸到处都是梗。
还有一个大家非常喜欢的、印了很多常用终端指令的方块;下一届新队员面试的时候就直接对着这个问就好了 hh。

非常感谢~
Related posts