华为昇腾910使用初探
post on 21 Mar 2021 about 15064words require 51min
CC BY 4.0 (除特别声明或转载文章外)
如果这些文字帮助到你,可以请我喝一杯咖啡~
在本文中,我使用华为 Atlas 800-9000 训练服务器上的 Ascend 910 AI 加速卡上跑了一个 MatMul 算子,并对调用 AscendCL 接口的地方分别计时,从而大致了解使用 NPU 启动一次计算的流程和各部分耗时情况。
实验环境
可以看到,机器的配置符合官网上的说明,单机有八张昇腾 910A 加速卡,而单卡空转待机功率接近七十瓦。Ascend 910 似乎有 A、B、Pro 等若干后缀小版本,而它们之间的差异似乎在软件层面是不可见的。
此外在 npu 面板中可以看到,其中有两个占用:Memory-Usage 和 HBM-Usage。初次看到的时候让我迷惑了一下,后查阅文档得知,Atlas 系列的加速卡上本身就有运行一个 device OS,这使得它可以工作在 EP 模式和 RC 模式下。所谓 EP 模式和我们平时的 GPU 比较类似,由 host 机的 CPU 调度 AICore,Device 上的 CPU 几乎处于不可见状态;而 RC 模式下可以直接通过 Device 上的 AI CPU 启动程序,并且(从代码示例)来看 AI CPU 可以直接对 HBM 进行寻址,无需再走 PCI-E 总线,感觉和 nvidia 之前出的 DPU 有些像,大约可以应用于边缘计算的场景。因此 HBM 接近于我印象中的显存,而另一者就不是今天主要关注的对象了。
使用自带的算力测试工具 ascend-dmi -f跑一下,单卡在默认参数下跑出 262 TFLOPS,相对于官网上宣称的 320 TFLOPS 理论值来说可以接受。注意到此时功耗约 240W,离最大功耗 310W 还有一段距离,感觉还有提升的空间。
服务器的 CPU 也值得单独提一下,共有四块鲲鹏 920,是(我)少见的用于服务器的 arm CPU。另外在官网上看到鲲鹏 920 似乎有 32/48/64 多个版本的配置,而我手上的是 48 核版。就使用体验来看很让我惊喜,arm 在服务端上也可以有 Intel Xeon Gold 同一量级的性能。不过在 /proc/cpuinfo 中缺失了 CPU 型号相关的信息,有些可惜。
最后这台服务器实际上是有其他人在用的,(小小吐槽一下)/usr目录下的软件管理比较混乱,使用时经常报错。因此接下来除驱动外我统一使用自己安装在用户目录下的软件环境。CANN 我统一使用自己下载的 20.1.rc1_linux-aarch64 社区版,因为接下来使用到的部分接口(aclopCompileAndExecute)似乎在新版本的文档中去掉了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
$ npu-smi info
+-------------------------------------------------------------------------------------------+
| npu-smi 1.7.6 Version: 20.1.0 |
+-------------------+-----------------+-----------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) |
| Chip | Bus-Id | AICore(%) Memory-Usage(MB) HBM-Usage(MB) |
+===================+=================+=====================================================+
| 0 910A | OK | 68.4 40 |
| 0 | 0000:C1:00.0 | 0 459 / 15307 0 / 32255 |
+===================+=================+=====================================================+
| 1 910A | OK | 65.5 35 |
| 0 | 0000:81:00.0 | 0 784 / 15689 0 / 32255 |
+===================+=================+=====================================================+
| 2 910A | OK | 66.8 34 |
| 0 | 0000:41:00.0 | 0 1098 / 15689 0 / 32255 |
+===================+=================+=====================================================+
| 3 910A | OK | 66.9 40 |
| 0 | 0000:01:00.0 | 0 2496 / 15601 0 / 32255 |
+===================+=================+=====================================================+
| 4 910A | OK | 66.7 39 |
| 0 | 0000:C2:00.0 | 0 153 / 15307 0 / 32255 |
+===================+=================+=====================================================+
| 5 910A | OK | 65.0 34 |
| 0 | 0000:82:00.0 | 0 313 / 15689 0 / 32255 |
+===================+=================+=====================================================+
| 6 910A | OK | 67.5 34 |
| 0 | 0000:42:00.0 | 0 784 / 15689 0 / 32255 |
+===================+=================+=====================================================+
| 7 910A | OK | 66.3 40 |
| 0 | 0000:02:00.0 | 0 3276 / 15601 0 / 32255 |
+===================+=================+=====================================================+
$ ascend-dmi -f
-----------------------------------------------------------------------------------------
Device Execute Times Duration(ms) TFLOPS@FP16 Power(W)
-----------------------------------------------------------------------------------------
0 192,000,000 1536 262.144 239.716
-----------------------------------------------------------------------------------------
$ cat /proc/cpuinfo | grep processor | wc -l
192
$ cat /proc/cpuinfo | head -n 10
processor : 0
BogoMIPS : 200.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop
CPU implementer : 0x48
CPU architecture: 8
CPU variant : 0x1
CPU part : 0xd01
CPU revision : 0
processor : 1
$ cat /proc/meminfo
MemTotal: 803585472 kB
MemFree: 578641344 kB
MemAvailable: 704245568 kB
Buffers: 3136 kB
Cached: 206471232 kB
SwapCached: 0 kB
Active: 12392256 kB
Inactive: 194916672 kB
Active(anon): 3918336 kB
Inactive(anon): 1231232 kB
Active(file): 8473920 kB
Inactive(file): 193685440 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 39063488 kB
SwapFree: 39063488 kB
Dirty: 384 kB
Writeback: 0 kB
AnonPages: 835008 kB
Mapped: 132096 kB
Shmem: 4315072 kB
Slab: 9605440 kB
SReclaimable: 6719360 kB
SUnreclaim: 2886080 kB
KernelStack: 138560 kB
PageTables: 17152 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 440856192 kB
Committed_AS: 5693952 kB
VmallocTotal: 133009637312 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 524288 kB
$ uname -a
Linux atlas01 4.14.0-115.el7a.0.1.aarch64 #1 SMP Sun Nov 25 20:54:21 UTC 2018 aarch64 aarch64 aarch64 GNU/Linux
$ spack debug report
* **Spack:** 0.16.1
* **Python:** 3.7.5
* **Platform:** linux-centos7-aarch64
$ spack unload -a
$ spack load [email protected]
$ spack find --loaded
==> 6 installed packages
-- linux-centos7-aarch64 / [email protected] ----------------------------
[email protected] [email protected] [email protected] [email protected] [email protected] [email protected]
$ which $CXX
~/spack-0.16.1/opt/spack/linux-centos7-aarch64/gcc-4.8.5/gcc-7.5.0-4euuqqu5srdpm6hxg4kuwhoyjc6crp2t/bin/g++
实验结果及分析
几个简单总结:
- 创建上下文、申请内存、释放内存、释放上下文、去初始化的开销都很大,需要尽量避免
- 算子首次编译需要 12s 左右的时间,后续运行无需重新编译
- Memset 开销远低于 Malloc,应当尽量多复用内存
- FP16MatMul 算子运行时间已经低于将矩阵从内存拷贝到设备的开销!
- GEMM 算子不支持 FP32
- GEMM 算子和使用 FP32 的 MatMul 算子性能很低,鸡肋
- 切换上下文开销很低
- 由于创建释放上下文的开销仍然很高,必要时仍要使用 stream
- 经过热身的 MatMul 算子可以在
{m, n, k} == {8192, 8192, 8192}问题规模的 FP16 矩阵乘法上跑出接近 200 TFLOPS 的算力,远优于同期发布的 NVIDIA V100S 只有 130TFLOPS 的 FP16 理论算力(使用 Tensor Core)。- 当然,一年后发布的 NVIDIA A100 使用 Tensor Core 的理论 FP16 算力达到 312TFLOPS,已经处于同一水平了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ ./MatMul 8192 8192 8192
aclInit: 4.422000 ms, 0.000000e+00 FLOPS
aclrtCreateContext: 351.026000 ms, 0.000000e+00 FLOPS
aclrtSetCurrentContext: 0.006000 ms, 0.000000e+00 FLOPS
aclrtMalloc: 198.336000 ms, 0.000000e+00 FLOPS
aclrtMallocHost: 26.796000 ms, 0.000000e+00 FLOPS
aclrtMemsetAsync: 77.729000 ms, 0.000000e+00 FLOPS
aclrtMemcpyAsyncHtoD: 36.260000 ms, 0.000000e+00 FLOPS
Cast(aclFloat16): 0.498000 ms, 0.000000e+00 FLOPS
Cast(float): 0.484000 ms, 0.000000e+00 FLOPS
MatMulV2(aclFloat16): 5.613000 ms, 1.958866e+14 FLOPS
MatMulV2(float): 1154.355000 ms, 9.524900e+11 FLOPS
MatMul(aclFloat16): 5.610000 ms, 1.959914e+14 FLOPS
MatMul(float): 1154.473000 ms, 9.523927e+11 FLOPS
GEMM(aclFloat16): 202.152000 ms, 5.439034e+12 FLOPS
aclrtMemcpyAsyncDtoH: 11.689000 ms, 0.000000e+00 FLOPS
aclrtFree: 59.107000 ms, 0.000000e+00 FLOPS
aclrtFreeHost: 64.095000 ms, 0.000000e+00 FLOPS
aclrtDestroyContext: 186.624000 ms, 0.000000e+00 FLOPS
aclFinalize: 349.656000 ms, 0.000000e+00 FLOPS
实验代码 MatMul.cc
华为官方提供了一个 gemm 算子示例,提供了封装后的 GEMM 算子使用方法。但是我在实验中发现,这个封装的 aclblasGemmEx 接口仍然存在诸多问题:
- 使用这个封装后的接口时,居然还需要在程序运行前确定所有可能会遇到的矩阵规模和存储格式,再用 ATC 工具将算子提前编译成二进制文件!诚然,这样固定问题规模的设计,有利于对不同的输入做编译期的优化,但是使用起来无疑是非常不方便的。
- 截至目前, 接口输入输出矩阵的 LD 只支持
-1,由输入矩阵的格式推断。这和上面固定问题规模的问题一起,导致不能像 cuBLAS 一样做到即开即用,使用前基本都需要重新对数据进行打包。 - GEMM 算子的性能非常低,在官方示例的基础上各种调整,也最多只能在
{m, n, k} == {20000, 20000, 20000}的问题规模上得到不到 10TFLOPS 的算力。
关于第三点,我找到 Ascend910 对应的达芬奇架构设计图:
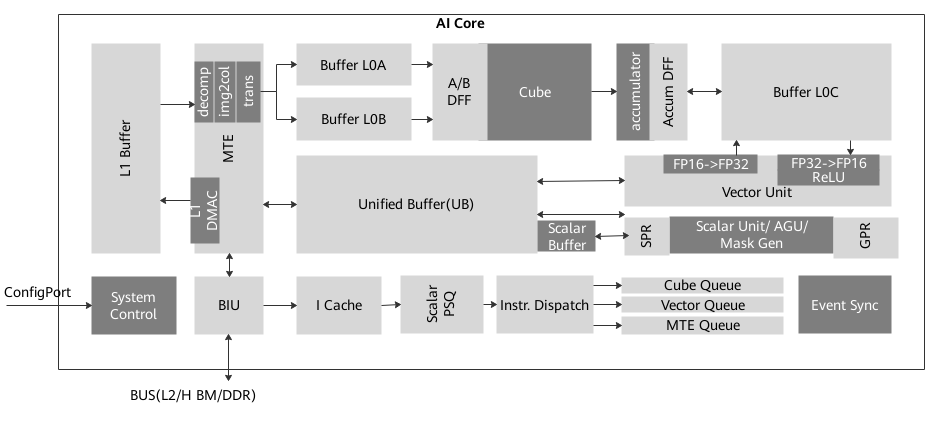
再结合文档里可知,矩阵运算和向量运算属于两条流水队列(共有五条)的,猜测 GEMM 算子内部混合使用了两个运算单元且流水调度做的比较差。而因为文档里的这句话说,华为没有开放 Cube 单元和 Vector 单元混合编程的接口,因此没有继续探索手动控制流水线这条不归路了。
当前仅支持用户开发 Vector 算子,由于开发高性能 Cube 算子难度较大,暂由华为交付。
因此本例中,相较于 GEMM 算子,我运行的是 CANN V100R020C10 算子清单 (训练) 01 中查到的 MatMul 算子,从而真正发挥 NPU 的算力。
此外我使用了 20.1.rc1 版本中 fwkacllib 库提供的 aclopCompileAndExecute 接口,它可以在运行期异步编译并执行指定的算子。这个接口更适合那些首次启动性能不那么重要的场合(也可以在启动时做热身操作),比如端上的应用。需要注意的是,在后续版本的文档中移除了这个接口,这个特性可能仍处于开发阶段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
/*
export DDK_PATH=~/Ascend/ascend-toolkit/20.1.rc1/arm64-linux
$CXX -std=c++11 -I$DDK_PATH/fwkacllib/include -L$DDK_PATH/fwkacllib/lib64 \
-lascendcl -lacl_op_compiler -o MatMul MatMul.cc
./MatMul 8192 8192 8192
*/
#include <acl/acl.h>
#include <acl/acl_op_compiler.h>
#include <functional>
#include <string>
#include <sys/time.h>
#define ACLCHECK(cmd) \
do { \
int e = cmd; \
if (e != ACL_ERROR_NONE) { \
fprintf(stderr, "%d", e); \
exit(1); \
} \
} while (0)
void WuK_Timer(const char *tag, float flo, const std::function<void()> &kernel,
int test_time = 1) {
double min_time = 9e99;
while (test_time--) {
struct timeval start, end;
gettimeofday(&start, NULL);
kernel();
gettimeofday(&end, NULL);
min_time = std::min(min_time, (end.tv_sec - start.tv_sec) * 1e3 +
(end.tv_usec - start.tv_usec) * 1e-3);
}
fprintf(stdout, "%s: %f ms, %e FLOPS\n", tag, min_time, flo * 1e3 / min_time);
}
int main(int argc, char **argv) {
int64_t m = std::stoi(argv[1]), n = std::stoi(argv[2]),
k = std::stoi(argv[3]), dimA[] = {m, k}, dimB[] = {k, n},
dimC[] = {m, n}, sAsize = (m * k * sizeof(float) + 63) / 32 * 32,
sBsize = (k * n * sizeof(float) + 63) / 32 * 32,
sCsize = (m * n * sizeof(float) + 63) / 32 * 32,
sALPHAsize = (sizeof(float) + 63) / 32 * 32,
sBETAsize = (sizeof(float) + 63) / 32 * 32,
hAsize = (m * k * sizeof(aclFloat16) + 63) / 32 * 32,
hBsize = (k * n * sizeof(aclFloat16) + 63) / 32 * 32,
hCsize = (m * k * sizeof(aclFloat16) + 63) / 32 * 32,
hALPHAsize = (sizeof(aclFloat16) + 63) / 32 * 32,
hBETAsize = (sizeof(aclFloat16) + 63) / 32 * 32;
aclTensorDesc
*sAdesc = aclCreateTensorDesc(ACL_FLOAT, 2, dimA, ACL_FORMAT_ND),
*sBdesc = aclCreateTensorDesc(ACL_FLOAT, 2, dimB, ACL_FORMAT_ND),
*sCdesc = aclCreateTensorDesc(ACL_FLOAT, 2, dimC, ACL_FORMAT_ND),
*sALPHAdesc = aclCreateTensorDesc(ACL_FLOAT, 0, dimC, ACL_FORMAT_ND),
*sBETAdesc = aclCreateTensorDesc(ACL_FLOAT, 0, dimC, ACL_FORMAT_ND),
*sDesc[] = {sAdesc, sBdesc, sCdesc, sALPHAdesc, sBETAdesc},
*hAdesc = aclCreateTensorDesc(ACL_FLOAT16, 2, dimA, ACL_FORMAT_ND),
*hBdesc = aclCreateTensorDesc(ACL_FLOAT16, 2, dimB, ACL_FORMAT_ND),
*hCdesc = aclCreateTensorDesc(ACL_FLOAT16, 2, dimC, ACL_FORMAT_ND),
*hALPHAdesc = aclCreateTensorDesc(ACL_FLOAT16, 0, dimC, ACL_FORMAT_ND),
*hBETAdesc = aclCreateTensorDesc(ACL_FLOAT16, 0, dimC, ACL_FORMAT_ND),
*hDesc[] = {hAdesc, hBdesc, hCdesc, hALPHAdesc, hBETAdesc};
aclopAttr *attrMatMul = aclopCreateAttr(), *attrGEMM = aclopCreateAttr(),
*attrCastFp16 = aclopCreateAttr(),
*attrCastFp32 = aclopCreateAttr();
ACLCHECK(aclopSetAttrBool(attrMatMul, "transpose_x1", 0));
ACLCHECK(aclopSetAttrBool(attrMatMul, "transpose_x2", 0));
ACLCHECK(aclopSetAttrBool(attrGEMM, "transpose_a", 0));
ACLCHECK(aclopSetAttrBool(attrGEMM, "transpose_b", 0));
ACLCHECK(aclopSetAttrInt(attrCastFp16, "dst_type", ACL_FLOAT16));
ACLCHECK(aclopSetAttrInt(attrCastFp32, "dst_type", ACL_FLOAT));
WuK_Timer("aclInit", 0, [&] { ACLCHECK(aclInit(NULL)); });
aclrtContext HPLAI_ACL_BLASPP_CONTEXT;
WuK_Timer("aclrtCreateContext", 0, [&] {
uint32_t deviceId = 0, count = 0;
aclrtGetDeviceCount(&count);
ACLCHECK(aclrtCreateContext(&HPLAI_ACL_BLASPP_CONTEXT, deviceId % count));
});
WuK_Timer("aclrtSetCurrentContext", 0, [&] {
ACLCHECK(aclrtSetCurrentContext(HPLAI_ACL_BLASPP_CONTEXT));
});
void *HPLAI_ACL_BLASPP_HOST_BUFFER, *HPLAI_ACL_BLASPP_DEVICE_BUFFER;
int64_t HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE =
sAsize + sBsize + sCsize + sALPHAsize + sBETAsize,
HPLAI_ACL_BLASPP_DEVICE_BUFFER_SIZE =
HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE + hAsize + hBsize + hCsize +
hALPHAsize + hBETAsize;
WuK_Timer("aclrtMalloc", 0, [&] {
ACLCHECK(aclrtMalloc(&HPLAI_ACL_BLASPP_DEVICE_BUFFER,
HPLAI_ACL_BLASPP_DEVICE_BUFFER_SIZE,
ACL_MEM_MALLOC_HUGE_FIRST));
});
WuK_Timer("aclrtMallocHost", 0, [&] {
ACLCHECK(aclrtMallocHost(&HPLAI_ACL_BLASPP_HOST_BUFFER,
HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE));
});
char *sAdevice = (char *)HPLAI_ACL_BLASPP_DEVICE_BUFFER,
*sBdevice = sAdevice + sAsize, *sCdevice = sBdevice + sBsize,
*sALPHAdevice = sCdevice + sCsize,
*sBETAdevice = sALPHAdevice + sALPHAsize,
*hAdevice = sBETAdevice + sBETAsize, *hBdevice = hAdevice + hAsize,
*hCdevice = hBdevice + hBsize, *hALPHAdevice = hCdevice + hCsize,
*hBETAdevice = hALPHAdevice + hALPHAsize,
*sAhost = (char *)HPLAI_ACL_BLASPP_HOST_BUFFER,
*sBhost = sAhost + sAsize, *sChost = sBhost + sBsize,
*sALPHAhost = sChost + sCsize, *sBETAhost = sALPHAhost + sALPHAsize;
WuK_Timer("aclrtMemsetAsync", 0, [&] {
ACLCHECK(aclrtMemsetAsync(HPLAI_ACL_BLASPP_HOST_BUFFER,
HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE, 0,
HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
});
WuK_Timer("aclrtMemcpyAsyncHtoD", 0, [&] {
ACLCHECK(aclrtMemcpyAsync(
HPLAI_ACL_BLASPP_DEVICE_BUFFER, HPLAI_ACL_BLASPP_DEVICE_BUFFER_SIZE,
HPLAI_ACL_BLASPP_HOST_BUFFER, HPLAI_ACL_BLASPP_HOST_BUFFER_SIZE,
ACL_MEMCPY_HOST_TO_DEVICE, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
});
aclDataBuffer *sAdata = aclCreateDataBuffer(sAdevice, sAsize),
*sBdata = aclCreateDataBuffer(sBdevice, sBsize),
*sCdata = aclCreateDataBuffer(sCdevice, sCsize),
*sALPHAdata = aclCreateDataBuffer(sALPHAdevice, sALPHAsize),
*sBETAdata = aclCreateDataBuffer(sBETAdevice, sBETAsize),
*sData[] = {sAdata, sBdata, sCdata, sALPHAdata, sBETAdata},
*hAdata = aclCreateDataBuffer(hAdevice, hAsize),
*hBdata = aclCreateDataBuffer(hBdevice, hBsize),
*hCdata = aclCreateDataBuffer(hCdevice, hCsize),
*hALPHAdata = aclCreateDataBuffer(hALPHAdevice, hALPHAsize),
*hBETAdata = aclCreateDataBuffer(hBETAdevice, hBETAsize),
*hData[] = {hAdata, hBdata, hCdata, hALPHAdata, hBETAdata};
WuK_Timer(
"Cast(aclFloat16)", 0,
[&] {
ACLCHECK(aclopCompileAndExecute("Cast", 1, sDesc, sData, 1, hDesc,
hData, attrCastFp16, ACL_ENGINE_SYS,
ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"Cast(float)", 0,
[&] {
ACLCHECK(aclopCompileAndExecute(
"Cast", 1, hDesc + 2, hData + 2, 1, sDesc + 2, sData + 2,
attrCastFp32, ACL_ENGINE_SYS, ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"MatMulV2(aclFloat16)", 2.0 * m * n * k,
[&] {
ACLCHECK(aclopCompileAndExecute(
"MatMulV2", 2, hDesc, hData, 1, hDesc + 2, hData + 2, attrMatMul,
ACL_ENGINE_SYS, ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"MatMulV2(float)", 2.0 * m * n * k,
[&] {
ACLCHECK(aclopCompileAndExecute(
"MatMulV2", 2, sDesc, sData, 1, sDesc + 2, sData + 2, attrMatMul,
ACL_ENGINE_SYS, ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"MatMul(aclFloat16)", 2.0 * m * n * k,
[&] {
ACLCHECK(aclopCompileAndExecute("MatMul", 2, hDesc, hData, 1, hDesc + 2,
hData + 2, attrMatMul, ACL_ENGINE_SYS,
ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"MatMul(float)", 2.0 * m * n * k,
[&] {
ACLCHECK(aclopCompileAndExecute("MatMul", 2, sDesc, sData, 1, sDesc + 2,
sData + 2, attrMatMul, ACL_ENGINE_SYS,
ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer(
"GEMM(aclFloat16)", 2.0 * m * n * k,
[&] {
ACLCHECK(aclopCompileAndExecute("GEMM", 5, hDesc, hData, 1, hDesc + 2,
hData + 2, attrGEMM, ACL_ENGINE_SYS,
ACL_COMPILE_SYS, NULL, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
},
10);
WuK_Timer("aclrtMemcpyAsyncDtoH", 0, [&] {
ACLCHECK(aclrtMemcpyAsync(sChost, sCsize, sCdevice, sCsize,
ACL_MEMCPY_DEVICE_TO_HOST, NULL));
ACLCHECK(aclrtSynchronizeStream(NULL));
});
ACLCHECK(aclDestroyDataBuffer(sAdata));
ACLCHECK(aclDestroyDataBuffer(sBdata));
ACLCHECK(aclDestroyDataBuffer(sCdata));
ACLCHECK(aclDestroyDataBuffer(sALPHAdata));
ACLCHECK(aclDestroyDataBuffer(sBETAdata));
ACLCHECK(aclDestroyDataBuffer(hAdata));
ACLCHECK(aclDestroyDataBuffer(hBdata));
ACLCHECK(aclDestroyDataBuffer(hCdata));
ACLCHECK(aclDestroyDataBuffer(hALPHAdata));
ACLCHECK(aclDestroyDataBuffer(hBETAdata));
aclopDestroyAttr(attrCastFp32);
aclopDestroyAttr(attrCastFp16);
aclopDestroyAttr(attrGEMM);
aclopDestroyAttr(attrMatMul);
WuK_Timer("aclrtFree", 0,
[&] { ACLCHECK(aclrtFree(HPLAI_ACL_BLASPP_DEVICE_BUFFER)); });
WuK_Timer("aclrtFreeHost", 0,
[&] { ACLCHECK(aclrtFreeHost(HPLAI_ACL_BLASPP_HOST_BUFFER)); });
WuK_Timer("aclrtDestroyContext", 0,
[&] { ACLCHECK(aclrtDestroyContext(HPLAI_ACL_BLASPP_CONTEXT)); });
WuK_Timer("aclFinalize", 0, [&] { ACLCHECK(aclFinalize()); });
}
Related posts