分布式系统·作业(二)
post on 29 Sep 2019 about 8520words require 29min
CC BY 4.0 (除特别声明或转载文章外)
如果这些文字帮助到你,可以请我喝一杯咖啡~
从典型的开源分布式系统如下(不限于):
- 分布式文件系统(HDFS、NFS、Ceph)
- 分布式数据库(Mongodb、Cassandra、ElasticSearch)
- 分布式处理框架(Hadoop、MPI、Spark、Storm)
- 分布式调度器(YARN、Mesos、Slurm)
- 分布式操作系统(Kubernetes、OpenStack、OpenShift)
找出分别符合集中式体系结构、非集中组织结构、混合组织结构的分布式系统,并从这些系统中选择3∼4个系统,找出其中能够体现分布式系统可扩展性、容错性的代码片段,并解释。
GlusterFS
GlusterFS(GNU ClusterFile System)是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点全部平等。相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。

上图是来自官方文档的架构示意图。可以看出,GlusterFS是符合非集中组织结构的分布式系统。
在glusterfs/libglusterfs/src/gfdb/gfdb_data_store.c的第77~171行,找到了一些插入/删除节点相关的函数,体现了GlusterFS的可扩展性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
/*Internal Function: Adds connection node to the end of
* the db connection list.*/
static int
add_connection_node(gfdb_conn_node_t *_conn_node)
{
int ret = -1;
GF_ASSERT(_conn_node);
/*Lock the list*/
ret = pthread_mutex_lock(&db_conn_mutex);
if (ret) {
gf_msg(GFDB_DATA_STORE, GF_LOG_ERROR, ret, LG_MSG_LOCK_LIST_FAILED,
"Failed lock db connection "
"list %s",
strerror(ret));
ret = -1;
goto out;
}
if (db_conn_list == NULL) {
db_conn_list = _conn_node;
} else {
list_add_tail(&_conn_node->conn_list, &db_conn_list->conn_list);
}
/*unlock the list*/
ret = pthread_mutex_unlock(&db_conn_mutex);
if (ret) {
gf_msg(GFDB_DATA_STORE, GF_LOG_ERROR, ret, LG_MSG_UNLOCK_LIST_FAILED,
"Failed unlock db "
"connection list %s",
strerror(ret));
ret = -1;
goto out;
/*TODO What if the unlock fails.
* Will it lead to deadlock?
* Most of the gluster code
* no check for unlock or destroy of mutex!*/
}
ret = 0;
out:
return ret;
}
/*Internal Function:
* Delete connection node from the list*/
static int
delete_conn_node(gfdb_conn_node_t *_conn_node)
{
int ret = -1;
GF_ASSERT(_conn_node);
/*Lock of the list*/
ret = pthread_mutex_lock(&db_conn_mutex);
if (ret) {
gf_msg(GFDB_DATA_STORE, GF_LOG_ERROR, ret, LG_MSG_LOCK_LIST_FAILED,
"Failed lock on db connection"
" list %s",
strerror(ret));
goto out;
}
/*Remove the connection object from list*/
if (IS_THE_ONLY_NODE(_conn_node)) {
db_conn_list = NULL;
GF_FREE(_conn_node);
} else {
if (IS_FIRST_NODE(db_conn_list, _conn_node)) {
db_conn_list = list_entry(db_conn_list->conn_list.next,
gfdb_conn_node_t, conn_list);
}
list_del(&_conn_node->conn_list);
GF_FREE(_conn_node);
}
/*Release the list lock*/
ret = pthread_mutex_unlock(&db_conn_mutex);
if (ret) {
gf_msg(GFDB_DATA_STORE, GF_LOG_WARNING, ret, LG_MSG_UNLOCK_LIST_FAILED,
"Failed unlock on db "
"connection list %s",
strerror(ret));
/*TODO What if the unlock fails.
* Will it lead to deadlock?
* Most of the gluster code
* no check for unlock or destroy of mutex!*/
ret = -1;
goto out;
}
ret = 0;
out:
return ret;
}
在glusterfs/xlators/cluster/dht/src/dht-inode-read.c下,找到如下代码(766行~784行):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
int
dht_flush(call_frame_t *frame, xlator_t *this, fd_t *fd, dict_t *xdata)
{
xlator_t *subvol = NULL;
int op_errno = -1;
dht_local_t *local = NULL;
VALIDATE_OR_GOTO(frame, err);
VALIDATE_OR_GOTO(this, err);
VALIDATE_OR_GOTO(fd, err);
local = dht_local_init(frame, NULL, fd, GF_FOP_FLUSH);
if (!local) {
op_errno = ENOMEM;
goto err;
}
subvol = local->cached_subvol;
if (!subvol) {
gf_msg_debug(this->name, 0, "no cached subvolume for fd=%p", fd);
op_errno = EINVAL;
goto err;
}
if (xdata)
local->xattr_req = dict_ref(xdata);
local->call_cnt = 1;
STACK_WIND(frame, dht_flush_cbk, subvol, subvol->fops->flush, fd,
local->xattr_req);
return 0;
err:
op_errno = (op_errno == -1) ? errno : op_errno;
DHT_STACK_UNWIND(flush, frame, -1, op_errno, NULL);
return 0;
}
这个函数是用于多节点间数据的同步刷新。可以看到,代码中会在运行遇到故障时给出报错信息并跳转DHT_STACK_UNWIND函数做下一步处理,具有一定容错性。
Slurm
SLURM (Simple Linux Utility for Resource Management)是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统,被世界范围内的超级计算机和计算集群广泛采用。SLURM 维护着一个待处理工作的队列并管理此工作的整体资源利用。它以一种共享或非共享的方式管理可用的计算节点(取决于资源的需求),以供用户执行工作。SLURM 会为任务队列合理地分配资源,并监视作业至其完成。如今,SLURM 已经成为了很多最强大的超级计算机上使用的领先资源管理器,如天河二号上便使用了 SLURM 资源管理系统。
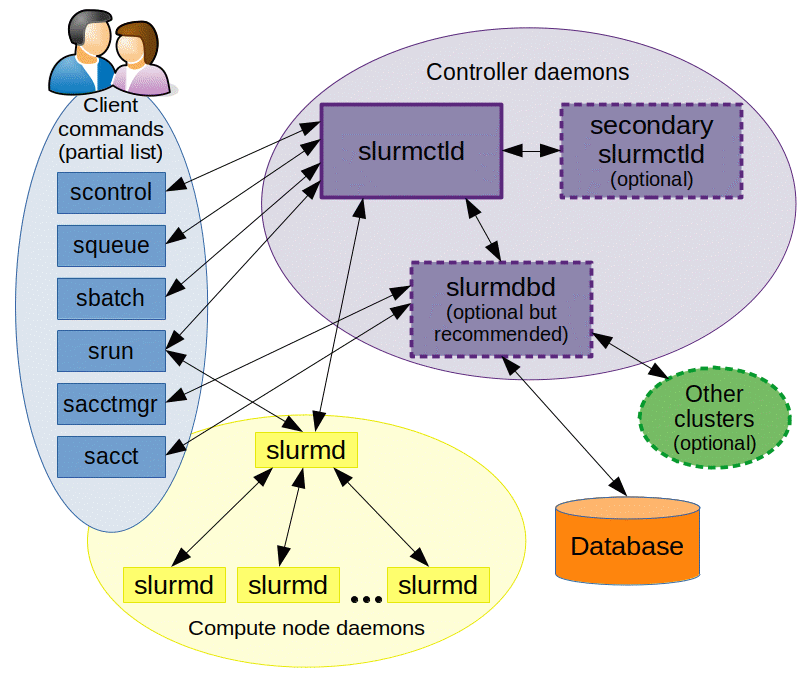
上图为Slurm架构图。可以看出,Slurm是典型的集中式体系结构,有具体的调度节点。
在Slurm的Github仓库中,找到了Slurm中更新节点的相关代码slurm/src/scontrol/update_node.c,下面截取54行开始的若干行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
extern int
scontrol_update_node (int argc, char **argv)
{
int i, j, rc = 0, update_cnt = 0;
update_node_msg_t node_msg;
char *reason_str = NULL;
char *tag, *val;
int tag_len, val_len;
slurm_init_update_node_msg(&node_msg);
for (i = 0; i < argc; i++) {
tag = argv[i];
val = strchr(argv[i], '=');
if (val) {
tag_len = val - argv[i];
val++;
val_len = strlen(val);
} else {
exit_code = 1;
error("Invalid input: %s Request aborted", argv[i])
return -1;
}
同时,在src/slurmctld/ping_nodes.c的127行处,也找到了这样一个函数,用于检测所有节点是否仍然有效,保证了整个集群不会因为某些结点的失效而出错,增加了一定的容错性。
1
2
3
4
5
6
7
8
9
10
11
12
/*
* ping_nodes - check that all nodes and daemons are alive,
* get nodes in UNKNOWN state to register
*/
void ping_nodes (void)
{
static bool restart_flag = true; /* system just restarted */
static int offset = 0; /* mutex via node table write lock on entry */
static int max_reg_threads = 0; /* max node registration threads
* this can include DOWN nodes, so
* limit the number to avoid huge
* communication delays */
Ray
Ray是UC Berkeley RISELab新推出的高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比Spark更优异的计算性能。

作为分布式计算系统,Ray仍旧遵循了典型的Master-Slave的设计:Master负责全局协调和状态维护,Slave执行分布式计算任务。不过和传统的分布式计算系统不同的是,Ray使用了混合任务调度的思路。在集群部署模式下,Ray启动了以下关键组件:
- GlobalScheduler:Master上启动了一个全局调度器,用于接收本地调度器提交的任务,并将任务分发给合适的本地任务调度器执行。
- RedisServer:Master上启动了一到多个RedisServer用于保存分布式任务的状态信息(ControlState),包括对象机器的映射、任务描述、任务debug信息等。
- LocalScheduler:每个Slave上启动了一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。
- Worker:每个Slave上可以启动多个Worker进程执行分布式任务,并将计算结果存储到ObjectStore。
- ObjectStore:每个Slave上启动了一个ObjectStore存储只读数据对象,Worker可以通过共享内存的方式访问这些对象数据,这样可以有效地减少内存拷贝和对象序列化成本。ObjectStore底层由Apache Arrow实现。
- Plasma:每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理,它可以在Worker访问本地ObjectStore上不存在的远程数据对象时,主动拉取其它Slave上的对象数据到当前机器。
Ray属于混合组织结构。
以下代码片段来自于ray/src/ray/raylet/scheduling_policy.cc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
std::vector<TaskID> SchedulingPolicy::SpillOver(
SchedulingResources &remote_scheduling_resources) const {
// The policy decision to be returned.
std::vector<TaskID> decision;
ResourceSet new_load(remote_scheduling_resources.GetLoadResources());
// Check if we can accommodate infeasible tasks.
for (const auto &task : scheduling_queue_.GetTasks(TaskState::INFEASIBLE)) {
const auto &spec = task.GetTaskSpecification();
const auto &placement_resources = spec.GetRequiredPlacementResources();
if (placement_resources.IsSubset(remote_scheduling_resources.GetTotalResources())) {
decision.push_back(spec.TaskId());
new_load.AddResources(spec.GetRequiredResources());
}
}
// Try to accommodate up to a single ready task.
for (const auto &task : scheduling_queue_.GetTasks(TaskState::READY)) {
const auto &spec = task.GetTaskSpecification();
if (!spec.IsActorTask()) {
// Make sure the node has enough available resources to prevent forwarding cycles.
if (spec.GetRequiredPlacementResources().IsSubset(
remote_scheduling_resources.GetAvailableResources())) {
decision.push_back(spec.TaskId());
new_load.AddResources(spec.GetRequiredResources());
break;
}
}
}
remote_scheduling_resources.SetLoadResources(std::move(new_load));
return decision;
}
可以发现,当有新的服务器/Worker加入时,很容易在new_load中通过AddResource添加新的worker,可扩展性很好。
同时,也在ray/src/ray/raylet/node_manager.cc的1477行处找到了一些处理任务失败的函数,表现了这个系统的容错性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
void NodeManager::TreatTaskAsFailed(const Task &task, const ErrorType &error_type) {
const TaskSpecification &spec = task.GetTaskSpecification();
RAY_LOG(DEBUG) << "Treating task " << spec.TaskId() << " as failed because of error "
<< ErrorType_Name(error_type) << ".";
// If this was an actor creation task that tried to resume from a checkpoint,
// then erase it here since the task did not finish.
if (spec.IsActorCreationTask()) {
ActorID actor_id = spec.ActorCreationId();
checkpoint_id_to_restore_.erase(actor_id);
}
// Loop over the return IDs (except the dummy ID) and store a fake object in
// the object store.
int64_t num_returns = spec.NumReturns();
if (spec.IsActorCreationTask() || spec.IsActorTask()) {
// TODO(rkn): We subtract 1 to avoid the dummy ID. However, this leaks
// information about the TaskSpecification implementation.
num_returns -= 1;
}
// Determine which IDs should be marked as failed.
std::vector<plasma::ObjectID> objects_to_fail;
for (int64_t i = 0; i < num_returns; i++) {
objects_to_fail.push_back(spec.ReturnId(i).ToPlasmaId());
}
const JobID job_id = task.GetTaskSpecification().JobId();
MarkObjectsAsFailed(error_type, objects_to_fail, job_id);
task_dependency_manager_.TaskCanceled(spec.TaskId());
// Notify the task dependency manager that we no longer need this task's
// object dependencies. TODO(swang): Ideally, we would check the return value
// here. However, we don't know at this point if the task was in the WAITING
// or READY queue before, in which case we would not have been subscribed to
// its dependencies.
task_dependency_manager_.UnsubscribeGetDependencies(spec.TaskId());
}
Related posts